Индексы относятся к важнейшим обобщающим показателям статистики.
Индекс – это относительный показатель сравнения двух состояний простого или сложного явления, состоящего из соизмеримых или несоизмеримых элементов, во времени или пространстве.
Основными задачами индексного метода являются:
ü оценка динамики обобщающих показателей, характеризующих сложные, непосредственно несоизмеримые совокупности;
ü анализ влияния отдельных факторов на изменение результативных обобщающих показателей;
ü анализ влияния структурных сдвигов на изменение средних показателей однородной совокупности;
ü оценка территориальных, в том числе международных, сравнений.
Индексы классифицируют постепени охвата, по базе сравнения, по виду весов, по форме построения и по составу явления. По степени охвата индексы бывают индивидуальные и общие (сводные). По базе сравнения – динамические, индексы выполнения плана, территориальные. По виду весов – с постоянными весами и с переменными весами.
Индексы в базе данных — ключ к оптимизации / Что это? Для чего нужны. Илья Хохлов
По форме построения – агрегатные и средневзвешенные. По составу явления – постоянного состава и переменного состава.
Общие (сводные) индексы бывают только групповые; динамические индексы бывают базисные и цепные; индексы с постоянными весами – стандартные, базисного периода, отчетного периода; средневзвешенные индексы – арифметические и гармонические.
Условные обозначения, используемые в теории индексного метода:
р -цена за единицу товара (услуги);
q -количество (объем) какого-либо продукта (товара) в натуральном выражении;
pq -общая стоимость продукции данного вида (товарооборот);
z -себестоимость единицы продукции (изделия);
zq -общая себестоимость продукции данного вида (денежные затраты на ее производство);
Т -общие затраты времени на производство продукции или общая численность работников;
w=q/T -производство продукции данного вида в единицу времени (либо выработка продукции на одного работника, т.е. производительность труда);
t=T/q -затраты рабочего времени на единицу продукции (трудоемкость единицы продукции);
1 -подстрочный символ показателя текущего (отчетного) периода;
0 -подстрочный символ показателя предшествующего (базисного) периода
Индивидуальные и общие индексы. Агрегатный индекс как основная форма общего индекса
Индивидуальный индекс (i) характеризует динамику уровня изучаемого явления во времени за два сравниваемых периода или выражает соотношение отдельных элементов совокупности.
Основным элементом индексного соотношения является индексируемая величина. Индексируемая величина – это признак, изменение которого характеризует индекс.
Основные формулы вычисления индивидуальных индексов:
Индекс физического объема (количества) продукции

Индекс цен

Индексы | Основы SQL
Индекс стоимости продукции

Индекс трудоемкости

Взаимосвязь индексов




Общий индекс (I) характеризует обобщающие результаты совместного изменения всех единиц, образующих статистическую совокупность. Общие индексы могут быть представлены в трех формах: агрегатной, средней арифметической, средней гармонической.
Исходной формой выражения сводного индекса является агрегатная форма.
Основные функции агрегатных индексов:
в индексе обобщаются (агрегируются) непосредственно несоизмеримые явления.
посредством индексного метода измеряется влияние отдельных факторов на совокупное изменение изучаемого показателя.
Основными элементами агрегатного индекса являются индексируемая величина и вес индекса. Индексируемая величина – признак, изменение которого характеризует индекс. Вес индекса — величинатесно связанная с индексируемой величиной и служащая для целей соизмерения индексируемых величин.
Основные формулы вычисления общих индексов:
Индекс стоимости продукции
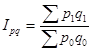

Индекс показывает во сколько раз возросла (уменьшилась) стоимость продукции в отчетном периоде по сравнению с базисным периодом за счет изменения цен на товары и объемов их производства или реализации.
Разность числителя и знаменателя показывает на сколько денежных единиц увеличилась (уменьшилась) стоимость продукции в текущем периоде по сравнению с базисным периодом за счет изменения цен на товары и объемов их реализации.
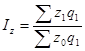
Индекс себестоимости продукции , где

— затраты на производство продукции (издержки производства) отчетного периода;
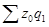
— затраты на производство той же продукции при условии, что себестоимость продукции остается на уровне базисного периода.
Индекс показывает во сколько раз изменились издержки производства продукции в отчетном периоде по сравнению с базисным периодом в результате изменения себестоимости продукции.
Разность числителя и знаменателя показывает на сколько денежных единиц изменились издержки производства в результате роста (уменьшения) себестоимости продукции.
Индекс физического объема продукции, взвешенный по себестоимости , где

— затраты на производство продукции (издержки производства) базисного периода.
Индекс показывает во сколько раз изменились издержки производства продукции в отчетном периоде по сравнению с базисным периодом в результате роста (уменьшения) объема ее производства.
Разность числителя и знаменателя — на сколько денежных единиц изменились издержки производства продукции в результате роста (уменьшения) объема ее производства.
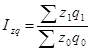
Индекс издержек производства (затрат на производство)
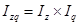
Индекс показывает во сколько раз возросли (уменьшились) издержки производства продукции в отчетном периоде по сравнению с базисным периодом в результате изменения себестоимости продукции и объема ее производства.
Разность числителя и знаменателя — на сколько денежных единиц увеличились (уменьшились) издержки производства продукции в текущем периоде по сравнению с базисным периодом за счет изменения себестоимости продукции и объема ее производства.

Индекс физического объема продукции, взвешенный по трудоемкости , где
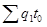
— условная величина, показывающая сколько времени пришлось бы затратить на производство всей продукции отчетного периода в базисном периоде.
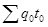
— фактические затраты времени на производство всей продукции в базисном периоде.
Индекс показывает во сколько раз возросли (уменьшились) затраты времени на производство продукции в отчетном периоде по сравнению с базисным периодом в результате изменения объема продукции.
Разность числителя и знаменателя — на сколько человеко-часов возросли (уменьшились) затраты времени на производство продукции в результате изменения объема производства продукции.
Индекс трудоемкости
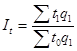
, где
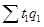
— фактические затраты времени на производство всей продукции в отчетном периоде.
Индекс показывает во сколько раз возросли (уменьшились) затраты времени на производство продукции в отчетном периоде по сравнению с базисным периодом в результате изменения трудоемкости.
Разность числителя и знаменателя — на сколько человеко-часов возросли (уменьшились) затраты времени на производство продукции в результате изменения трудоемкости.
Индекс производительности труда по трудовым затратам


Индекс показывает во сколько раз возросли (уменьшились) затраты времени на производство продукции в отчетном периоде по сравнению с базисным периодом в результате изменения производительности труда.
Разность числителя и знаменателя — на сколько человеко-часов возросли (уменьшились) затраты времени на производство продукции в результате изменения производительности труда.
Индивидуальный индекс
Агрегатный индекс
Пааше Ласпейреса
Производные индивидуальных индексов
Средний индекс




Индекс Физического объема
Средний индекс

Индекс Себестоимости
Индекс Трудоемкости
Цепные и базисные индексы
Индивидуальные индексы
Индекс физического объема
базисныецепные


Индекс цен
базисные цепные


Цепные индексы получаются из базисных путем деления данного базисного индекса на предыдущий:

. Произведение последовательных цепных индексов дает базисный индекс последнего периода:

Индекс физического объема
базисныецепные


Индекс цен
базисныецепные


Отношение базисного индекса отчетного периода к базисному индексу предшествующего периода дает цепной индекс отчетного периода:

.
Базисные индексы можно получить, перемножив последовательно цепные индексы, начиная с первого:

.
Индекс физического объема
базисныецепные


Индекс цен
базисныецепные


Для индексов с переменными весами переход от цепных индексов к базисным (и наоборот) невозможен.)
Контрольные вопросы для самоподготовки:
1. Понятие об индексах и их значение. Индивидуальные индексы и их виды (качественных и количественных величин, цепные и базисные).
2. Понятие об индексируемой величине и весах индекса. Общие индексы.
3. Агрегатный индекс как основная форма экономического индекса. Основные виды экономических индексов (Паше, Ласпейраса, Дюто, Карли).
4. Индексы постоянного, переменного состава и структурных сдвигов. Средний арифметический, средний гармонический индексы и индекс средних уровней.
5. Взаимосвязь цепных и базисных индексов. Индексы – дефляторы.
Список использованной литературы
Нормативно-правовые акты
1. Федеральный закон «Об официальном статистическом учете и системе государственной статистики в Российской Федерации» от 29 ноября 2007 года № 282-ФЗ.
2. Приказ Ростехрегулирования №329-ст от 22 ноября 2007 г. «О внедрении Общероссийского классификатора продукции по видам экономической деятельности (ОКПД)»
3. Федеральная целевая программа Развитие государственной статистики России в 2007-2011 годах.
4. Методологические положения по статистике. — М.: Росстат 2006 — Вып.5.
Базовый учебник
1. Статистика: Учебно-практич. пособие / Под. ред. М.Г. Назарова.- М.:КНОРУС,2006*;
2. Социально-экономическая статистика. Практикум / под ред. С.А. Орехова. – М.: Эксмо, 2007. – 384 с.*
Основная литература
1. Теория статистики: Учебник / Под ред. Р.А. Шмойловой.-5-е изд.- М.: Финансы и статистика, 2005;*
2. Практикум по теории статистики. Учебное пособие. /Под ред. Шмойловой Р.А. — М.: Финансы и статистика, 2002*;
3. Статистика финансов: Учеб. Пособие / под ред.М.Г. Назарова. – М: Омега-Л, 2005. – 380 с.*
4. Статистика: Учебник / Под ред. В.Г. Ионина.-3-е изд., перераб. и доп.-М.: ИНФРА-М, 2006*
Дополнительная литература
1. Статистика: Учебник / Под ред. И.И. Елисеевой.-М.: Высшее образование, 2006*;
2. Гусаров В.М. Статистика: Учеб. пособие для вузов. — М: ЮНИТИ-ДАНА, 2001*;
3. Статистика: Учебник / Под ред. B.C. Мхитаряна.-М.: Экономистъ, 2005*;
4. Статистика: Учеб.пособие / Под ред. В.М. Симчеры.- М.: Финансы и статистика, 2005*;
5. Салин В.Н., Чурилова Э.Ю. Курс теории статистики для подготовки специалистов финансово-экономического профиля: Учебник. — М.: Финансы и статистика, 2006*;
6. Журнал «Вопросы статистики».
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«АКАДЕМИЯ БЮДЖЕТА И КАЗНАЧЕЙСТВА
МИНИСТЕРСТВА ФИНАНСОВ РОССИЙСКОЙ ФЕДЕРАЦИИ»
КАЛУЖСКИЙ ФИЛИАЛ
Текст лекции
Тема: «Индексный метод»
Для студентов всех специальностей
Текст лекции рассмотрен и утвержден на заседании кафедры «Статистика» «__» __________ 2010 г., протокол № ____
| План лекции | стр. |
| 1. Понятие индексов в статистике. Классификация индексов | |
| 2. Индивидуальные и общие индексы. Агрегатный индекс как основная форма общего индекса | |
| 3. Средние индексы. Индексы средних уровней качественных показателей | |
| 4. Цепные и базисные индексы | |
| Контрольные вопросы | |
| Список использованной литературы |
Понятие индексов в статистике. Классификация индексов
Индексы относятся к важнейшим обобщающим показателям статистики.
Индекс – это относительный показатель сравнения двух состояний простого или сложного явления, состоящего из соизмеримых или несоизмеримых элементов, во времени или пространстве.
Основными задачами индексного метода являются:
ü оценка динамики обобщающих показателей, характеризующих сложные, непосредственно несоизмеримые совокупности;
ü анализ влияния отдельных факторов на изменение результативных обобщающих показателей;
ü анализ влияния структурных сдвигов на изменение средних показателей однородной совокупности;
ü оценка территориальных, в том числе международных, сравнений.
Индексы классифицируют постепени охвата, по базе сравнения, по виду весов, по форме построения и по составу явления. По степени охвата индексы бывают индивидуальные и общие (сводные). По базе сравнения – динамические, индексы выполнения плана, территориальные. По виду весов – с постоянными весами и с переменными весами.
По форме построения – агрегатные и средневзвешенные. По составу явления – постоянного состава и переменного состава.
Общие (сводные) индексы бывают только групповые; динамические индексы бывают базисные и цепные; индексы с постоянными весами – стандартные, базисного периода, отчетного периода; средневзвешенные индексы – арифметические и гармонические.
Условные обозначения, используемые в теории индексного метода:
р -цена за единицу товара (услуги);
q -количество (объем) какого-либо продукта (товара) в натуральном выражении;
pq -общая стоимость продукции данного вида (товарооборот);
z -себестоимость единицы продукции (изделия);
zq -общая себестоимость продукции данного вида (денежные затраты на ее производство);
Т -общие затраты времени на производство продукции или общая численность работников;
w=q/T -производство продукции данного вида в единицу времени (либо выработка продукции на одного работника, т.е. производительность труда);
t=T/q -затраты рабочего времени на единицу продукции (трудоемкость единицы продукции);
1 -подстрочный символ показателя текущего (отчетного) периода;
0 -подстрочный символ показателя предшествующего (базисного) периода
Источник: infopedia.su
Индексы в PostgreSQL
В статье я расскажу о предназначении и основах принципов работы объектов баз данных — индексов. На примере СУБД PostgreSQL коротко рассмотрим несколько разных типов индексов и классов задач, для которых они применимы. В конце материала поделюсь ссылками на статьи с более глубоким описанием внутреннего устройства индексов в PostgreSQL.
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Предназначение индексов
Простейший метод решения задачи поиска записей в базе данных, удовлетворяющих определенному критерию, — полный перебор. Но с ростом количества записей производительность такого подхода будет заметно падать. Для повышения производительности поиска создаются вспомогательные структуры — индексы. Используя индексы, можно существенно поднять скорость поиска, потому что данные в индексе хранятся в форме, позволяющей нам в процессе поиска не рассматривать области, которые заведомо не могут содержать искомые элементы.
Если провести аналогию между базой данных и книгой, индексами можно считать оглавление книги и предметный указатель. Действительно, если бы у нас не было таких «индексов», для поиска конкретной главы или для поиска определения какого-то понятия пришлось бы листать и читать всю книгу целиком, пока не найдем то, что нужно. Имея оглавление и предметный указатель, нам нужно просмотреть существенно меньший объем данных, после чего мы точно узнаем номер страницы книги, на которой находится то, что мы ищем. Индексы в базах данных по сути устроены так же, как оглавление или как предметный указатель книги.
Важно, что использование индексов не только сокращает время поиска в абсолютном выражении, но и уменьшает алгоритмическую сложность процесса поиска. Это значит, что время, необходимое на поиск с помощью индексов, при росте объема базы данных будет расти существенно медленнее, чем при использовании полного перебора.
В качестве примера рассмотрим задачу поиска в списке чисел. Используя перебор элементов списка, в худшем случае, нам придется просмотреть список целиком. Алгоритмическая сложность такого метода — O(n). Но если мы будем хранить наши числа особым образом — отсортированными по возрастанию или по убыванию — сможем использовать алгоритм бинарного поиска.
2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
Допустим, необходимо определить, содержит ли этот отсортированный список число 158. Для этого:
- Смотрим на число в середине списка — 114. Наш список отсортирован по возрастанию, и мы ищем число 158 > 114. Значит, левую половину списка до числа 114 мы можем отбросить: в ней гарантированно не может быть искомого элемента.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Теперь делаем то же самое для правой половины списка. В середине у нее число 134, значит, мы снова можем отбросить элементы левее.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Делаем то же самое для элементов правее 134. В середине у них число 158 — искомый элемент. Поиск закончен.
В итоге метод бинарного поиска дал нам результат всего за три шага. При полном переборе с начала списка нам потребовалось бы 16 шагов. Бинарный поиск имеет алгоритмическую сложность O(log(n)). Используя формулы алгоритмической сложности O(n) и O(log(n)), мы можем оценить, как будет меняться приблизительное количество операций при поиске разными способами с ростом объема данных:
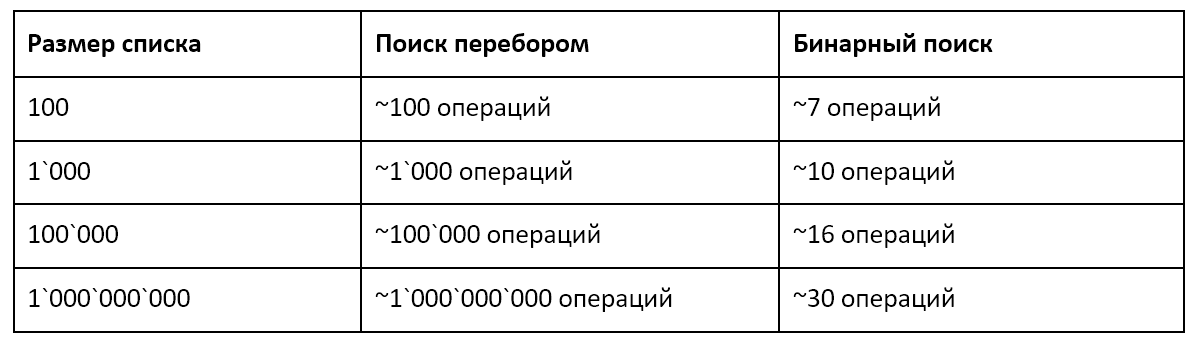
Результат впечатляет. Храня данные в отсортированном виде, мы не только снизили скорость поиска по ним, но и колоссально сократили скорость замедления поиска при росте объема данных.
Использование индексов в базе данных дает аналогичный результат. Принцип работы одного из важнейших индексов в базе данных (индекс на основе B-дерева) основан именно на рассмотренном нами выше принципе — возможности хранить данные в отсортированном виде.
Индексы в PostgreSQL
В базах данных, таких как PostgreSQL, индекс формируется из значений одного или нескольких столбцов таблицы и указателей на строки этой таблицы.
SELECT * FROM table_name WHERE P(column_name) = 1
Здесь выражение P(column_name) = 1 означает, что значение в колонке column_name удовлетворяет некоторому условию (предикату) P .
В отсутствии индекса для колонки column_name , PostgreSQL для выполнения этого запроса был бы вынужден просмотреть таблицу table_name целиком, вычисляя для каждой строки значение предиката P и, если значение истинно, добавлял бы строку к результатам запроса.
Имея индекс для колонки column_name , PostgreSQL может быстро, не просматривая таблицу целиком, получить из индекса указатели на строки таблицы, которые удовлетворяют условию P , и затем уже по этим указателям прочитать данные из таблицы и сформировать результат. Это аналогично тому, как мы, вместо того чтобы просматривать всю книгу целиком, смотрим только ее оглавление, читаем номера страниц, соответствующие интересующим нам главам, а затем переходим на эти страницы.
Предикат P может вычисляться от значения нескольких колонок. В этом случае для ускорения запроса используется индекс, построенный не для одной колонки, а для нескольких. Такие индексы называют составными.
Если мы хотим ускорить выполнение запроса, условие которого вычисляется по одной или нескольким колонкам, в PostgreSQL нам необходимо создать для этих колонок индекс с помощью команды CREATE INDEX :
Эта команда имеет большой перечень дополнительных параметров, с полным списком которых можно ознакомиться в документации.
Например, индекс может поддерживать ограничение на уникальность и не допускать появления в таблице нескольких строк, значения индексируемых столбцов у которых совпадают. Для этого при создании индекса указывают ключевое слово UNIQUE :
Или мы можем создать индекс не по полю таблицы, а по функции или скалярному выражению с одной или несколькими колонками таблицы (такие индексы называют функциональными или индексами по выражению). Это позволяет быстро находить данные в таблице по результатам вычислений. Например, мы хотим ускорит запрос регистронезависимого поиска по текстовому полю:
Если мы создадим обычный индекс по полю text_field , он нам никак не поможет, т. к. PostgreSQL проиндексирует те значения, которые хранятся в этом поле в исходном виде (необязательно в нижнем регистре), а мы хотим искать по значениям этого поля, приведенные к нижнему регистру вызовом функции lower . Однако мы можем создать индекс по результатам вычисления выражения lower(text_fields) :
CREATE INDEX index_name ON table_name(lower(text_field))
И такой индекс уже может успешно применяться для ускорения нашего запроса.
В зависимости от типа индексируемых данных, для индексирования применяются разные подходы. По умолчанию при создании индекса используется индекс на основе B-дерева. Но PostgreSQL поддерживает разные типы индексов для очень широкого круга задач, и при необходимости мы можем указать другой тип индекса, отличный от B-tree. Для этого перед списком индексируемых полей необходимо указать директиву USING . Например, для использования индекса типа GiST:
CREATE INDEX index_name ON table_name USING GIST (column_name)
B-tree
Этот тип индекса используется по умолчанию и покрывает очень широкий круг задач (базы данных большинства приложений успешно могут обходиться только индексами на основе B-деревьев).
С помощью B-дерева можно проиндексировать любые данные, которые могут быть отсортированы, т. е. для которых применимы операции сравнения больше/меньше/равно. Сюда можно отнести числа, строки, даты и время, логический тип и любые данные, которые можно ими закодировать.
Какой тип запросов может быть ускорен с помощью B-дерева? На самом деле, практически любой запрос, условие которого является выражением, состоящим из полей входящих в индекс, логических операторов и операций равенства/сравнения. Например:
Выполнение этих и многих других запросов может быть ускорено с помощью B-дерева. Кроме того, индекс на основе B-дерева ускоряет сортировку результатов, если в ORDER BY указано проиндексированное поле.
Принцип работы индекса на основе B-дерева основан на рассмотренном нами ранее алгоритме бинарного поиска: т. к. все значения упорядочены, мы можем быстро определять области, в которых гарантированно не может быть данных, удовлетворяющих запрос, существенно снижая таким образом количество перебираемых записей.
Однако хранить индекс просто в виде отсортированного массива мы не можем, т. к. данные могут модифицироваться: значения могут меняться, записи — удаляться или добавляться. Чтобы эффективно поддерживать хранение индексируемых данных в отсортированном виде, индекс хранят в виде сбалансированного сильно ветвящегося дерева, называемого B-деревом (B-tree).

Корневой узел B-дерева содержит в упорядоченном виде несколько значений из общего набора, допустим, t элементов. Тогда все остальные элементы можно распределить по t+1 дочерним поддеревьям по следующему правилу:
- Первое поддерево будет содержать элементы, которые меньше, чем 1-й элемент корневого узла (на рисунке выше первое поддерево содержит числа, меньшие 30).
- Второе поддерево будет содержать элементы, которые находятся между 1-м и 2-м элементами корневого узла (на рисунке выше второе поддерево содержит числа между 30 и 70).
- И т. д. — последнее поддерево будет содержать элементы, большие элемента корневого узла с номером t (на рисунке выше третье поддерево содержит элементы, большие 70).
Каждое поддерево, в свою очередь, тоже является B-деревом, имеет корневой элемент и строится далее рекурсивно по такому же принципу.
За счет того что элементы в каждом узле отсортированы, при поиске мы сможем быстро определить, в каком поддереве может находиться искомый элемент, и не рассматривать вообще другие поддеревья. Допустим, нам нужно найти число 67:
- Корневой узел содержит числа 30 и 70, значит, искомый элемент следует искать во втором поддереве, т.к. 67 > 30 и 67 < 70.
- Корневой узел второго поддерева содержит элементы 40 и 50. Т. к. 67 > 50, искомый элемент следует искать в третьем потомке этого узла.
- На третьем шаге мы получили узел, не имеющий потомков, среди элементов которого находим искомое число 67.
Таким образом, при поиске в B-дереве необходимо максимум h раз выполнить линейный или бинарный поиск в относительно небольших списках, где h — это высота дерева. Т.к. B-дерево — сильно-ветвящееся и сбалансированное (т. е. при его построении и модификации применяются алгоритмы, сохраняющие его высоту минимальной, см. статью), число h обычно совсем невелико, и при росте общего количества элементов оно растет логарифмически. Как мы уже видели ранее, это приносит очень хорошие результаты.

Кроме того, важное и полезное свойство B-дерева при его использовании в СУБД — возможность эффективно хранить его во внешней памяти. Каждый узел B-дерева обычно хранит такой объем данных, который может быть эффективно записан на диск или прочитан за одну операцию ввода-вывода. B-дерево даже может не помещаться целиком в оперативной памяти. В этом случае СУБД может держать в памяти только узлы верхнего уровня (которые вероятно будут часто использоваться при поиске), читая узлы нижних уровней только при необходимости.
Индекс на основе B-дерева может ускорять запросы, которые используют не целиком входящие в индекс поля, а любую часть, начиная с начала. Например, индекс может ускорить запрос LIKE для поиска строк, которые начинаются с заданной подстроки:
SELECT * FROM table_name WHERE text_field LIKE ‘start_substring%’
Если индекс построен по нескольким колонкам, он может ускорять запросы, в которых фигурируют одна или несколько первых колонок. Поэтому важен порядок, в котором мы указываем колонки при создании индекса. Допустим, у нас есть индекс по колонкам col_1 и col_2. Тогда он может использоваться в том числе для ускорения запроса вида:
SELECT * FROM table_name WHERE col_1 = 123
И нам не нужно создавать отдельный индекс для колонки col_1. Будет использоваться составной индекс (col_1, col_2).
Однако для запроса только по колонке col_2 такой составной индекс уже использовать не получится.
Подробнее, как индекс на основе B-дерева реализован в PostgreSQL, см. статью.
GiST и SP-GiST
GiST — сокращение от «generalized search tree». Это сбалансированное дерево поиска, точно так же, как и рассмотренный ранее b-tree. Но b-tree применимо только к тем типам данных, для которых имеет смысл операция сравнения и есть возможность упорядочивания. Но PostgreSQL позволяет хранить и такие данные, для которых операция упорядочивания не имеет смысла, например, геоданные и геометрические объекты.
Тут на помощь приходит индексный метод GiST. Он позволяет распределить данные любого типа по сбалансированному дереву и использовать это дерево для поиска по самым разным условиям. Если при построении B-дерева мы сортируем все множество объектов и делим его на части по принципу больше-меньше, при построении GiST индексов можно реализовать любой принцип разбиения любого множества объектов.
Например, в GiST-индекс можно уложить R-дерево для пространственных данных с поддержкой операторов взаимного расположения (находится слева, справа; содержит и т. д.). Такой индекс доступен в PostgreSQL и может быть полезен при разработке геоинформационных систем, в которых возникают запросы вида «получить множество объектов на карте, находящихся от заданной точки на расстоянии не более 1 км».
SP-GiST похож GiST, но он позволяет создавать несбалансированные деревья. Такие деревья могут быть полезны при разбиении множества на непересекающиеся объекты. Буквы SP означают space partitioning. К такому типу индексов можно отнести kd-деревья, реализация которых присутствует в PostgreSQL. Его, как и R-дерево, можно использовать для ускорения запросов геометрического поиска.
Свойство непересечения упрощает принятие решений при вставке и поиске. С другой стороны, получающиеся деревья, как правило, слабо ветвисты, что усложняет их эффективное хранение во внешней памяти.
Кроме того, GiST и SP-GiST могут служить своеобразным фреймворком, облегчающим расширение PostgreSQL и добавление в него совершенно новых видов деревьев для индексации новых типов данных.
Подробнее об алгоритмах, лежащих в основе R- и kd-деревьев см. раз и два, а об их реализации и использовании в PostgreSQL см. в этой и этой статье.
Заключение
Индексы — важнейший инструмент баз данных, ускоряющий поиск. Он не бесплатен, создавать много индексов без лишней необходимости не стоит — индексы занимают дополнительную память, и при любом обновлении проиндексированных данных СУБД должна выполнять дополнительную работу по поддержанию индекса в актуальном состоянии.
Источник: tproger.ru
Для чего НЕ нужны индексы
Индекс лишним не бывает? Чем больше индексов, тем лучше? А не проиндексировать ли это измерение на всякий случай? Если подобные вопросы иногда возникают в вашей голове, то эту статью прочитать было бы весьма полезно.
Итак, традиционное мнение, что «Индекс это хорошо, а блокировка это плохо», часто бывает неверным до противоположности.
Картинка выше, которую я выбрал для заголовка статьи, очень часто напоминает многие базы 1С, которые неожиданно начинают «быстро расти»и «тормозить».
Но прежде чем перейти к сути, придётся немного покопаться в теории.
Что такое индексы, для чего они нужны, какие они бывают?
Далее будет немного теории, объясняемой простым языком. Если все эти вопросы вам давно известны и вы считаете, что нет необходимости в таком примитивном объяснении, то вы, наверное, слишком редко заглядывали в доработки конфигураций, да что и говорить, в типовые конфигурации 3-4 летней давности, в любом случае, этот раздел всегда можно пропустить.
Итак, как работает индекс? Наверное, все в детстве играли в игру «угадай число»? Кто-то загадал число от 1 до 50, а вам его нужно угадать за наименьшее число вопросов.
Как вы будете его угадывать? Перебором: «Это 1? Это 2? Это 3?». Скорее всего, вы будете задавать вопросы вида: «Оно больше 25?». И только когда вариантов останется около 2-3, вы будете перебирать возможные.
Т.е. поступите примерно так, как показано на картинке:
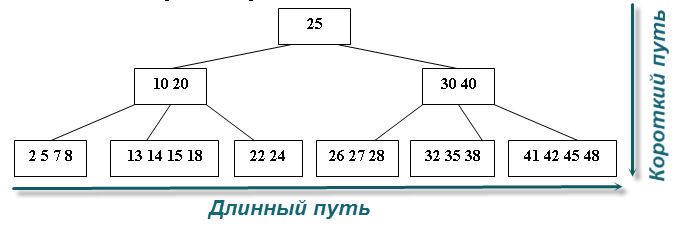
В ВУЗ-е мы уже узнаём, что подобные структуры называются графами, вернее, даже разновидностью графа — деревьями. Бывают ещё более вырожденные разновидности деревьев, так называемые B-деревья.
Собственно, они и лежат в основе большей части индексов.
Хотя, конечно, не большей. Индексы делятся на два типа: кластерные и не кластерные.
Конечно, можно вспомнить, что есть битовые индексы, функциональные индексы, XML индексы.
Но принципиальным отличаем будем считать физическую организацию и принцип работы.
Кластерный индекс — это по сути дела не индекс, а определенным образом организованная таблица. В Oracle его, к примеру, вообще называют Index Organized Table или IOT.
Некластерный индекс — это отдельная структура, как правило, вида B-дерева, которая создаётся дополнительно к основной таблице.
Если вы сейчас думаете, что эти два вида индексов придумали ИТ специалисты, то вы сильно ошибаетесь.
Вот так выглядит кластерный индекс, который появился ещё до появления компьютера:

А как-то вот так, соответственно, некластерный:

Данная аналогия оказывается на удивление полной.
Каким образом вам бы удобнее было искать? Сразу выбрать страницу, начиная с той буквы, которая указана на срезанных полях,
или сначала заглянуть в предметный указатель, потом узнать там номер страницы и уже искать нужную страницу по номеру?
Конечно, первый способ куда удобнее. Но вот только не очень он гибкий. обычно на полях ставят только буквы.
Нельзя написать целое слово или несколько слов, в то время как в предметном указателе их можно организовать как угодно.
Кроме того, предметный указатель по сути ссылается на номера страниц книги, на которых расположена нужная информация.
Сами номера страниц являются при этом по сути кластерным индексом.
Теперь давайте посмотрим уже более детально, применительно к MS SQL Server:
В MS SQL существуют 2 физических операции Index Seek и Index Scan. Index Seek — это хорошо, Index Scan — плохо.
Index seek означает просмотр индекса в порядке упорядочивания, либо по B-Дереву, Index Scan — обычная операция просмотра всех
записей таблицы, аналогичная всем известной Table Scan. Чаще всего данная операция присутствует в случае «неполного покрытия» индекса,
Если в индексе, к примеру, есть поле «Контрагент, Номенклатура» а отобрать записи надо по «контрагенту, номенклатуре и заказу покупателя».
В этом случае в плане запроса MS SQL можно будет увидеть что-то вида:
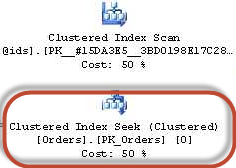
Т.е. сначала по индексу были выбраны записи, соответствующие покрытию, а остаток записей был получен полным последовательным просмотром таблицы.
А если мы сделаем у таблицы не кластерный индекс, то в итоге увидим примерно следующую картину:
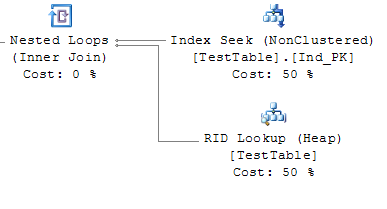
Тут есть ещё одна интересная операция — RID Lookup, занимающая целых 50% времени — столько же, сколько поиск по индексу.
Собственно, дополнительная операция требуется из-за того, что некластерный индекс не производит выборку по самой физической таблице, следовательно, требуется ещё сам поиск нужной физической страницы, чтобы считать сами данные.
Но в данном случае есть ещё одна специфика — это слово «Heap», указанное в скобках операции. Но о нём далее.
Чем плохи индексы?
1) Накладные затраты при записи данных
Очевидно, что для поддержания какой-либо дополнительной структуры данных, либо определенной организации данных, требуется совершать дополнительные действия.
Действий не так много, накладные затраты на них небольшие. Но плохо то, что эти затраты и действия возникают при записи данных. А запись данных происходит в транзакции.
Хуже если в транзакции происходит и запись и чтение данных (контроль остатков). В этом случае индекс должен быть всегда в актуальном состоянии.
Затраты на запись или чтение в транзакции намного «дороже» внетранзакционных издержек. Дело в том, что запись может вестись строго последовательно, и время на фиксацию изменений в БД сократить достаточно сложно. Более мощное оборудование тут не всегда помогает.
Внетранзакционное же чтение данных может вполне успешно выполняться параллельно, при этом в случае увеления количества запросов на чтение данных, к примеру, вследствие роста количества пользователей, то они вполне могут решиться наращиванием аппаратных ресурсов.
2) Накладные затраты на обслуживание индексов
При интенсивной записи данных в таблицу данные индексов к ней не всегда распологаются на той странице, на которой должны. Появляются «пропуски», физическая структура индексов становится неэффективной. Поэтому иногда бывает необходимо производить дефрагментацию индексов. Производительность запросов к СУБД во время дефрагментации, соответственно, падает. Есть ещё процесс полного перестроения индексов — но в современных версиях MS SQL необходимости выполнения данной операции по регламенту нет.
3) Влияние индексов на размер базы
Не самое страшное последствие, но так или иначе если база весит 150-200 ГБ, то об этом надо уже задуматься. Для средней OLTP базы размер индексов, как правило, превышает объём самой базы.
Не верите? Вполне можете воспользоваться какой-либо обработкой вроде этой: //infostart.ru/public/19463/ и посмотреть, сколько же в вашей базе места занимают индексы.
4) Затраты на создание и поддержание актуальной статистики
Статистику в базе нужно регулярно обновлять при интенсивных операциях вставки и обновления. Это занимает вычислительные ресурсы, хоть и не влияет непосредственно на процесс.
Неактуальная статистика может привести к проблемам производительности системы.
Но это не значит, что индексы — это плохо, без них СУБД были бы бесполезны. Плохи индексы, которые не используются.
Как оптимизатор выбирает, какой индекс ему использовать? (статистика, плотность, селективность, кардинальность)
Итак, про то, что «статистика должна быть» и «её нужно обновлять», слышали, наверное, все.
Многие даже знают, что нужно обновлять статистику, наизусть помнят запрос:
EXEC sp_MSForEachTable ‘UPDATE STATISTICS ? WITH FULLSCAN;’
Главное — не забыть, что хитрый MS SQL кэширует планы запроса, которые он уже раз посчитал. Даже если статистика изменится,
для того, чтобы что-то заработало по-другому, надо бы выполнить:
Но гораздо реже люди заморачиваются с тем, чтобы посмотреть статистику БД. Давайте попробуем это сделать на тестовой таблице:
Сделаем в БД простейшую таблицу следующего вида:
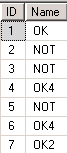
DBCC SHOW_STATISTICS(‘TAB’, NAME)
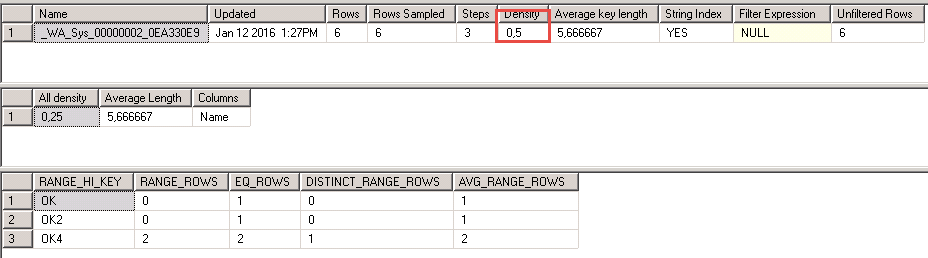
Оказывается, сколько всего сохраняется для такой маленькой таблицы. Интересен ещё тот факт, что вы же не выполняли никакого кода по созданию статистики.
Если статистика для таблицы не отключена, то она создаётся сама. И это тоже ложится на накладные расходы.
Сейчас нам интересен в этой таблице столбец Density — Плотность записей. Плотность рассчитывается как
Плотность = Число дубликатов в колонке / Общее число записей в таблице
И является одним из самых выжных статистических показателей данных в таблице. Очевидно, что чем меньше плотность записей, тем эффективнее можно будет воспользоваться индексом.
А при плотности 0.5, как в приведённом примере, индекс в принципе вообще не нужен. Чем ниже в таблице значение Density, тем более правильно спроектирована данная таблица.
Для СУБД лучше всего таблицы с уникальными записями. Обратите внимание на столбец All density — его значение уже 0.25. Это означает, что в таблице есть ещ одна колонка. Для MS SQL этот показатель важен, когда вы пишете «СГРУППИРОВАТЬ ПО».
Но плотности записей оптимизатору недостаточно. Основная задача оптимизатора — «догадаться», сколько строк вернёт запрос.
Допустим, у нас в базе куча складов по всем регионам — небольшие торговые точки + виртуальные склады. И есть один центральный склад.
Плотность по складу будет достаточно неплохая. Но вот число строк по центральному складу, которое вернёт запрос, и по региональному будет различаться в тысячи раз.
Для этого есть показатель селективности:
Селективность=число строк удовлетворяющих предикату/всего строк в таблице
Предикат — определенное условие.
Из картинки выше селективность определяется в третьей таблице. Там указан «ключ» — RANDE_HI_KEY и соответственно количество строк ему соответствующее. и количество значений, ему соответствующее в таблице.
Ну, и остался последний показатель статистики:
Кардинальность — это и есть предположительное число строк, которое вернёт запрос
В каждом элементе плана запроса этот показатель присутствует.
Если навести на элемент плана запроса курсор, то его можно увидеть во всплывающей подсказке примерно так:
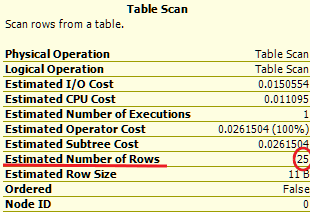
Итак, если итоговый запрос возвращает половину таблицы или около того, то индекс тут совсем не нужен.
Вспомним УТ 10.2, 10.1, даже 10.3, по-моему. В каждом документе был индекс по полю «Организация». В последних версиях его нет. Как думаете, почему?
Индекс также бесполезен, если оптимизатор MS SQL решает, что итоговый запрос вернёт половину таблицы или вроде того.
Почему MS SQL так может решить, вроде разобрались.
Теперь самое время разобраться, какие индексы есть в 1С:
Всё просто. Все объекты 1С делятся на ссылочные (у которых есть ссылка и, соответственно, GUID) и табличные (регистры).
У всех таблиц 1С есть кластерный индекс.
У ссылочных кластерный индекс создаётся по ссылке (GUID) — это самая быстрая выборка, которая только может быть.
У табличных кластерный индекс создаётся по всем изменениям. Что тоже предельно логично. И, конечно, этот индекс уникальный.
А как же затраты на запись? Зачем создавать кластерный индекс везде?
Дело тут в том, что так работает MS SQL. В стандартной таблице просто должен быть кластерный индекс.
Без него выборка из этой таблицы будет приводить к тому, что операция поиска записи по индексу (как было на картинке выше) будет занимать непростительно много времени.
В MS SQL таблицы без кластерного индекса называют Heap Table — куча. Что примерно соответствует их физической организации.
Тем не менее, такие таблицы могут быть важны. Если у вас 99% операций в этой таблице — запись, а для анализа этих данных вы, к примеру, применяете отдельное OLAP решение.
Поэтому возможность убирать кластерные индексы из таблиц очень бы не помешала разработчикам 1С.
Когда вы ставите у какого либо реквизита, ресурса или измерения объекта 1С признак «индексировать» — создаётся дополнительный или обновляется существующий не кластерный индекс для этой таблицы.
Включая реквизиты объекта в критерий отбора, вы также создаёте по ним отдельный индекс.
Это лишь общие правила, по которым платформа создаёт индексы на уровне СУБД. В каких-то деталях они могут отличаться, тем более в разных версиях платформы.
К счастью, 1С не пожадничали и дали нам инструмент, чтобы структуру БД просматривать — я про фукнкцию «ПолучитьСтруктуруХранения()».
Умельцы этой функцией воспользовались и сделали для неё неплохой интерфейс, которым можно вопспользоваться, чтобы точно посмотреть, какие же есть индексы у таблицы:
Зачем я всё это прочитал?
Что делать простому разработчику 1С?
Простой разработчик в отличие от оптимизатора MS SQL может заранее предсказать, какие будут данные в запросе, какие будут предикаты и какие нужны индексы.
Что же нужно делать, чтобы ваши запросы выполнялись быстро и при этом при записи данных в БД это не приводило к перезаписи нескольких десятков бесполезных индексов.
Делайте индексы, покрывающие предикаты, если данный запрос планируется к использованию достаточно часто. Но не забудьте, что уже существуют кластерные индексы.
Если находится индекс, уже покрывающий предикат в запросе, не создавайте нового индекса.
Если индекс покрывает почти всё условие запроса — оцените число записей, которое придётся перебрать СУБД при данной выборке, если оно невелико (менее нескольких тысяч) — не создавайте нового индекса
Определите селективность и/или плотность записей в выборке так, как их определит в данном случае оптимизатор. Если в итоговой выборке получится много записей по отношению к общему числу записей в таблице — не создавайте индекса, он лишний
Когда пишете запрос, думайте о том, как его будет анализировать оптимизатор, сможет ли он корректно посчитать ориентировочное число строк, возвращаемое каждой частью запроса.
В конце концов проверьте план полученного запроса, если он вам действительно важен, особенно если данный запрос нужно выполнять в транзакции.
Специальные предложения












Почитал с удовольствием. Есть еще программисты, способные просто и доступно разъяснять непростые для понимания вещи. Большое спасибо.
(4) baton_pk, Честно забыл про них, пока пусть так повесит, сам просвещусь какие там индексы и поправлю 🙂
(4) baton_pk, не только регистры расчета. Если регистр сведений периодический (кроме по подчинению регистратору) и у него нет измерений, то кластерный индекс также не создается. Платформа 8.3.7
(13) Irwin,
8.3.7 я ещё не смотрел, но ИТС пишет следующее:
Периодический регистр сведений
Индекс: [ОРРХ | ОРНР1 +] Период + [Измерение1 + . ] (Кластерный)
Условие и описание: Всегда.
PS. Или имелся ввиду НЕпериодический?
(14) baton_pk, как раз периодический, но без измерений (исключая периодичность по позиции регистратора).
Это лишь общие правила, по которым платформа создаёт индексы на уровне СУБД. В каких-то деталях они могут отличаться, тем более в разных версиях платформы.
Это ваще что?
Зачем умные ребята из микрософт понаделали «хороших» и «плохих» операторов? Почему не сделали только хороших?
Индекс скан будет использоваться в случае «неполного покрытия»?? О_О
Ну ребята то сделали только хорошие операторы. Будь воля MS SQL он бы всегда делал только Index Seek. Но вот прикладные разработчики 1С регулярно вынуждают его пользоваться index scan 🙂
А еще индекс не нужен для маленьких таблиц. Интересно вот с какого размера индекс начинает себя оправдывать?
Вспомним УТ 10.2, 10.1, даже 10.3, по-моему. В каждом документе был индекс по полю «Организация». В последних версиях его нет. Как думаете, почему?
Как на счет включения в базе ограничения по RSL с ограничением по полю организация? Как написано в методике от 1С: при выполнении запросов в которых происходит соединение, условие и т.п. по полям, то соответствующие поля должны быть проиндексированы. Так в итоге индексы должны быть?
RLS конечно :). Тут всё зависеть будет опять же от селективности. условия соединения. 1С в методике «не лезли в дебри» а написали как будет верно в общем случае. Если у вас в базе 10-ок организаций SQL соединит эти таблицы вложенными циклами, и просмотрев всю таблицу и будет полностью прав, следовательно индекс там не сдался. Но это не отменяет того что RLS вам внесёт полный хаус в запросы к БД и что в итоге получится надо смотреть только в профайлере 🙂
Ну что, книжку Филиппова пополам с методичкой с «1С-Эксперта» более-менее пересказал в общих чертах, молодец.
. интересно, долго ещё на Инфостарте будет пользоваться такой популярностью завуалированный плагиат?
Источники не книжка Филиппова, в которой эти вопросы незаслуженно упущены.
Был такой сайт — SQLCMD. там человек оочень подробно объяснял селективность, плотность, кардинальность. Сейчас сайт закрыли, у меня только архив остался.
В русскоязычном варианте аналогов не видел.
Оcновной англоязячный источник: Inside the SQL Server Query Optimizer — Benjamin Nevarez
И Grant Fritchey, SQL Server Query Perfomance Tuning
+ личный опыт конечно.
Вы видимо из статьи прочитали только начало (теорию) и конец (краткие рекоммендации), которые есть везде, но лишними не будут.
Был такой сайт — SQLCMD. там человек оочень подробно объяснял селективность, плотность, кардинальность. Сейчас сайт закрыли, у меня только архив остался.
В русскоязычном варианте аналогов не видел.
В текстовом формате действительно информации мало. На techdays есть видео доклад «О самой частой причине выбора нестабильного/неэффективного плана запроса, или Оценка Кардинальности: что это такое, и как с ней бороться» в двух частях от Алексея Эксаревского про кардинальность, оценку стоимости запроса и все что с этим связано. Много, местами скучновато но подробно и с примерами.
Там можно скачать видео и презентацию. Сам не смотрел ещё.
Кстати, советую ещё Pro SQL Server Internals — чтиво очень хорошо проясняет картину мира.
Ещё наверное полезно было бы SQLCMD архив выложить. Сайт закрыт, поэтому наверное ни чьи (с) я не нарушу.
Плюсаните пост, пусть вверх всплывёт, глядишь кто-нибудь ещё прочитает и станет больше суммарных знаний в мире 1С 🙂
А архивчик со статьями только в самом посте внизу подцепился 🙁
val_lime; st4rk; akR00b; BomjBandit; roman72; EVKash; ajax_new; mega; mvxyz; nvv1970; alex3067; SirStefan; agro23; Danil.Potapov; WizaXxX; oleg21592; TreeDogNight; Arrigo; gaglo; ikekoval; zzz14; Sergey.Noskov; AlX0id; Bronislav; ivanov660; _Z1; tormozit; + 27 – Ответить
(23) Спасибо за архив.
Жалко только что нет комментариев к статьям.
в комментариях тоже были очень ценные сведения.
По статье в чем то Вы не совсем правы. ( но обсуждение этого на мой взгляд принесет
вреда больше чем пользы — тем более это Ваша статья — Ваше виденье ms sql )
(23) да, это те самые ссылки, качества лучше не нашел, но это не принципиальный момент.
По индексам так же есть отличный доклад Дмитрия Короткевича https://www.techdays.ru/videos/4303.html новичкам в разработке (особенно уверенным что чем больше индексов тем лучше) смотреть обязательно.
(26) Sergey.Noskov, Пасиб. Включил в «заплюсованый» пост. Судя по всему соберём инфу в комментах и включу в основную статью 🙂
3) Если индекс покрывает почти всё условие запроса — оцените число записей, которое придётся перебрать СУБД при
данной выборке, если оно невелико (менее нескольких тысяч) — не создавайте нового индекса
(35) baton_pk, Ну я ещё до 8.3 писал что нужно бы включать: http://infostart.ru/public/91879/ и 8.3 тут не причём, если не полениться то можно сделать «жизнь чуть более приятной».
чревато волной статей «как я гордо восстанавливал базу после своих кривых рук»
(63) покажи мне базу данных, в которую данные не пишутся, а как у тебя записи в таблице возникают, селектом? или рассказываешь про удобную часть, а неудобная за рамками статьи?
(67) Gilev.Vyacheslav, Ну ты же изначально писал про дедлоки. которые возникают потому что при переборе записей они блокируются.
Так вот, в версионнике такая блокировка не приводит к дедлоку.
У меня в режиме версионирования дедлоки только при обменах возникают. Но с ними разделаться получилось только отказавшись от обменов 🙂
(68) я изначально писал что глупость рекомендовать «не создавать индексы», провоцируя захват избыточных данных
если в каком-то режиме не будет дедлоков, то вылезет таймаут/отсутвие версии или прочая «неприятность».
Не надо писать «не создавайте индексов если мало записей», не вводи в заблуждение людей.
ну на практике у меня таких «неприятностей» не возникало, когда лишние индексы посносил.
«Index Scan — обычная операция просмотра всех
записей таблицы, аналогичная всем известной Table Scan. Чаще всего данная операция присутствует в случае «неполного покрытия» индекса»
Здесь сразу несколько заблуждений.
1.1. Очень часто разработчики путают понятия покрывающего индекса и индекса подходящего под условия. Покрывающий индекс – это индекс который содержит в себе все поля возвращаемые в запросе, т.е. поля из раздела ВЫБРАТЬ. А индекс не подходящий под условия это как раз то, что вы описали.
1.2. Операция Scan всегда означает полный (а не частичный) просмотр всей таблицы или индекса, единственное исключение это когда в запросе есть ключевые слова ВЫБРАТЬ ПЕРВЫЕ тогда скан будет не всей таблицы/индекса, а только первых записей. Частичный скан в плане запроса будет выглядеть как оператор Seek но с условием Where, в графическом плане появится раздел Predicate.
2. По поводу чистки кэша после обновления статистики, сейчас SQL Server достаточно умный что бы самостоятельно перекомпилировать планы для тех таблиц, по которым было обновление статистики, не нужно этого делать еще раз.
3. У временных таблиц по умолчанию нет индексов. У регистра расчета нет кластерного индекса, но это все мелочи и можно посмотреть через вышеуказанную обработку.
4. Я бы дополнил статью разбором ситуаций, когда индекс есть но не может быть использован из-за неоптимально написанного запроса.
akR00b; Danil.Potapov; m.s.moiseev; oleg21592; temsan; Yashazz; gadjik; tormozit; Vladimir_Konyrev; Gilev.Vyacheslav; + 10 – 1 Ответить
(29) Andreynikus, 1.1 ну по контексту понятно наверное. неполное покрытие условий индекса имелось ввиду
1.2 так и написано вроде.
2 Тестил на 2012 — нифига он этого не делал. В SQLCMD человек тестил на 2008 — не делал. Поэтому ваше утверждение что «сейчас MS SQL достаточно умный». можно трактовать как «кому достаточно, а кому не достаточно». 2014 ещё дааалеко не у всех, и просто не проверял.
3 Ну конечно ориентировочно. Про регистры рассчетов забыл и уже указали
4 Этих ситуаций разбор это ещё на статью. притом не одну. Даже вон люди курсы отдельные придумали. Моя цель была чуть углубиться в работу оптимизитора. чтобы такие ситуации люди смогли разбирать сами.
(33)
2. А как вы тестили перекомпиляцию если не серкрет? На моих тестах все перекомпилирутся, главное что бы план был не тривиальный. Тем более что в документации MS SQL написано что после обновления планы будут перекомпилироваться https://msdn.microsoft.com/ru-ru/library/ms190397(v=sql.120).aspx а документации Microsoft в отличии от документации 1С в большинстве случаев можно верить 🙂
4. Насчет отдельных курсов на эту тему, можете ссылку кинуть?
Да ладно? :))) Создайте табличку, создаёте руками левую статистику, создаёте индекс и вызываете предполагаемый план выполнения. ИМХО если бы при каждом запросе к СУБД MS SQL пересчитывал статистику и перекомпилировал планы выполнения запросов вы бы наслаждались песочными часиками большую часть времени своей работы. Более детально в (23) архивчик скачайте и там есть эта тема подробно. SQL 2012/2008 работает точно так.
Про курсы это к Гилёву он там уже выше что-то предлагал в этом роде 🙂
(39)
Зачем смотреть предполагаемый план? Смотреть надо на фактический, они ведь могут отличаться.
Можете мне скинуть тот скрипт где создается такая таблица, меняется статистика а главное выполняется тот самый запрос? Или скажите точно где можно скачать этот пример.
Я еще раз повторю, если план запроса тривиальный, тогда естественно ничего перекомпилироваться не будет, в этом нет смысла.
ИМХО если бы при каждом запросе к СУБД MS SQL пересчитывал статистику и перекомпилировал планы выполнения запросов вы бы наслаждались песочными часиками большую часть времени своей работы.
Естественно СУБД не будет пересчитывать статистику при каждом выполнении запроса об этом никто и не говорит. Читайте пожалуйста внимательнее, план будет перекомпилироваться только если по таблице была обновлена статистика. То что перекомпиляция будет только один раз кажется на столько очевидным, что не требует уточнений.
Почти угадали. Только, к сожалению, не всё так просто.
Но дело в том что статистика сама не всегда обновится тогда когда нужно.
написал же — в (23) 2-я статья. Я тоже не всегда людям доверяю, поэтому всё смотрел и проверял сам, можете тоже проверить и убедиться, тем более полезно будет :).
вооо. Вы не пути истинном. А теперь осталось определить что понимается под «тривиальный». В плане может быть только 2 операции, но при этом если он не перекомпилится то вся база «станет . ом» 🙂
Почти угадали. Только, к сожалению, не всё так просто.
Но дело в том что статистика сама не всегда обновится тогда когда нужно.
Гадают цыганки, я это просто знаю 🙂
Давайте не будем увиливать от темы, я говорю про перекомпиляцию плана, а не про то что статистика не всегда обновляется когда это необходимо, это все таки разные вещи. Тем более не считаете же вы что люди пишущие документацию MS SQL будут нас дезинформировать?
Пример посмотрел, как я и ожидал увидел там тот же план исполнения, операторы плана никак не изменились ни до не после чистки кэша, стоимость плана та же, изменилось только предполагаемое число строк.
База встанет если люди по вашему совету будут использовать чистку процедурного кэша всего сервера в рабочее время, такого делать ни в коем случае нельзя. Если уж так приспичило чистить процедурный кэш, можно это делать хотя бы для одной базы, а не для всего сервера.
сущие мелочи в принципе. оно никак на план не влияет, и вообще SQL накой то фиг их считает, тратит лишнее время 🙂
конечно конечно. ни в коем случае нельзя. и статистику обновлять нельзя. оно всё само сделает, и вообще руками лучше не лезть — убъёт :). Не очищайте процедурный кэш, попробуйте на рабочем сервере пару дней. и ещё в базе в которой постоянно изменения, таблицы чистятся, запросы новые поялвяются.
Это лучшая рекоммендация в принципе. так к вам больше обращений будет ;). Которые очень легко решаются 🙂
(53)
Я вижу вы любите путать теплое с мягким, либо просто сами не понимаете о чем говорите. Дальнейший диалог считаю бессмысленным.
P.S. Ни одна из приведенных ссылок не отвечает полностью на вопрос, почему индекс не используется даже когда он существует, везде только обрывки информации, что только подтверждает сказанное выше.
Вы всё ещё верите в существовании полного и всеобъемлющего ответа на этот вопрос? А в Деда Мороза или Санта Клауса тоже? :))))
Есть такая поговорка: слышу звон да не знаю где он 🙂
Есть курсы по оптимизации 1С, которые кстати я и веду 🙂
Но тема индексов там лишь одна из многих тем. Отдельных курсов только про индексы, как вы написали, я не встречал, хотя с удовольствием бы на них сходил.
разбором ситуаций, когда индекс есть но не может быть использован из-за неоптимально написанного запроса
(46)
Не соглашусь с вам, информации в контексте 1С на этот счет крайне мало, да не в контексте 1С тоже не особо то много. Большая часть русскоязычных статей сводится к описанию того что является и что не является SARG аргументом, в лучшем случае еще селективность упомянут. Но ведь в этой теме есть еще много чего интересного.
(52) Andreynikus, Ой ну не смешите. Учимся пользоваться поиском. Только по инфостарту:
Отбалды в принципе, но прочитайте, ознакомьтесь — приобщитесь 🙂
1.2. . когда в запросе есть ключевые слова ВЫБРАТЬ ПЕРВЫЕ тогда скан будет не всей таблицы/индекса, а только первых записей. Частичный скан в плане запроса будет выглядеть как оператор Seek но с условием Where, в графическом плане появится раздел Predicate.
т.е. операция сканирования индекса, если в запросе указано ПЕРВЫЕ, в плане запроса будет отображаться как операция Seek (поиск)?
(43) Sergey.Noskov,
Это 2 разных предложения про две разные вещи.
Если указано ВЫБРАТЬ ПЕРВЫЕ тогда будет операция Scan но это не означает что будет скан всей таблицы/индекса, будет просто чтение нескольких первых записей.
Частичный скан это другая история никак не связанная с ВЫБРАТЬ ПЕРВЫЕ. Частичный скан — это когда часть данных ищется по индексу, а часть сканируется.
В таком случае, логично создать его вручную. Чем это может быть чревато? Ну, кроме нарушения соглашения 1С, конечно.
(89) «Кластерный индекс» — это абстракция, описывающая положение элементов таблицы при вставке. Создание кластерного индекса для таблицы расчетов по всей видимости бессмысленная затея. Как таковой «кластерный индекс» нигде не хранится — хранится только его описание.
(90) «Кластерный индекс» — это физическое сортировка записей регистра. Поэтому работа с ним быстрее, чем с некластерным индексом. Я так это понял.
Если у регистра есть индексы, почему бы не выяснить, какой индекс используется чаще и отсортировать таблицу в соответствии с этим индексом, то есть сделать его «кластерным»?
я вроде человек с высшим образованием (физик), а ничегошеньки не понял и, главное, ничего полезного не почерпнул. А где же конкретные примеры, как надо и как не надо использовать эти самые индексы? Может я такой «тугой», а все остальные такие «вумные», но для меня статья — «полный ноль». Даже те небольшие бесплатные видеоуроки с курсов 1С дали на порядок больше информации. Простите уж.
(30) Mortiferus, окай. Вот тебе одна из полезняшек:
Данные любой таблицы в MsSQL будут кластеризованы (грубо говоря идти в том-же порядке на жестком диске) по одному из индексов. Зная какой это индекс, можно заставить летать то, что летать не может. можно переработать запросы, существенно сократив время их выполнения. Как-раз для случая, когда вернется 50% таблицы, логично данные таблицы сложить по порядку на диске, в котором ожидается их чтение. Таким образом чтение станет последовательным как для данных, так и для индекса. Физика HDD?
Разумеется при использовании SSD положением данных на диске можно пренебречь. Но не другими благами кластеризации. Вообще жаль что вам не интересно. Проблема в том, что разработчики и доработчики конфигураций активно и бездумно добавляют индексы реквизитам объектов. Статья о них и скорее для них.
(31) fzt, немного не так. То, что записи в таблице отсортированы, не значит, что они так и хранятся.
Физически записи в кластерном индексе отсортированы только в пределах страницы. Сами страницы отсортированы логически – горизонтальными ссылками между страницами, но располагаться на диске могут как угодно. Поэтому никакого последовательного чтения не будет.
более того, даже сами записи не отсортированы, а лишь хранится отдельно в конце страницы список с необходимым порядком записей.
(55) Irwin,
Тем не менее, операция дефрагментации индексов будет пытаться их привести к такому порядку. Так что иногда все-таки может быть и последовательное чтение %)
(56) baton_pk,
А это с точки зрения головки HDD должно быть пофиг — читается всегда страница целиком.
Я старался, и у меня не получилось видимо :(. Почитайте Дейта попробуйте http://www.ozon.ru/context/detail/id/2309312/ потом вернитесь к статье.
Кажется, мы теряем правильное направление.
Раз сюда начали слетаться гуру, может, кто-нибудь подробнее расскажет нам про статистику?
Про то, что статистика строится по одному столбцу; про то, когда и как создаётся автоматическая статистика, про 200 шагов (почему их 200?); про автоматическое обновление статистики, автоматическое асинхронное обновление статистики — про это вообще некоторые такую бредятину несут иногда.
(47) так я и хотел бы увидеть объяснение «для всех», как в этой статье про индексы.
А не ссылку на статью, где лично я для себя нового ничего не открыл при беглом просмотре.
О_о. Я раза 4 читал и каждый раз открывал что-то новое. ну наверное ты просто глубоко очень разбираешься в деталях работы оптимизатора MS SQL. Про статистику конечно ещё есть что написать. Но тут наверное «простой 1С-ник» вряд ли на что-то сможет повлиять. Подумаю вообщем.
касаемо статьи в целом — почему не надо создавать индекс на каждый столбец и без этой статьи понятно — разумеется, индексы отлично себя показывают, пока вы выполняете запросы на выборку данных оператором SELECT, но как только начинается частый вызов операторов INSERT, UPDATE и DELETE, так пейзаж очень быстро меняется
но даже тут не все однозначно:
приоритеты задач тоже имеют значение — если мне нужно загрузить массив данных быстро в ущерб коллективной работе — я могу удалить хоть все индексы, если мне важнее коллективная параллельная работа, я наоборот пожертвую скоростью одного потока в пользу параллельности.
Прочитал. И комментарии тоже. Остались вопросы.
Давайте на конкретных примерах, прямо, чтобы вообще всем было понятно.
Например, самая распространенная ситуация сейчас: платформа 8.3, MS SQL, режим работы ReadCommitedSnapshot. Конфигурация на УФ, работа в тонком клиенте, управляемые блокировки. Сервер СУБД нормально настроен: статистика, шринк, реиндекс и все остальное. Если контора «побохаче», то для tempdb куплен промышленный ssd.
1. Есть большой регистр накопления, 5-7 измерений к примеру, несколько ресурсов, несколько реквизитов. Все измерения ссылочные. В регистр осуществляется частая параллельная запись по не пересекающимся (в абсолютном большинстве случаев) наборам данных, также часто идет чтение с помощью отчетов и контроля остатков при проведении документов.
Чтение возможно с отборами как по всем измерениям, так и по некоторым. В основном читаются итоги регистра, но в отдельных тяжелых отчетах, которые формируются не чаще нескольких раз в месяц — читается и физическая таблица, также с отборами по ну например 4 измерениям. Скорость записи в регистр является более приоритетна, чем чтение. Объем новых данных ежедневно — 5-7 тыс строк.
Как настроим индексы? Мне интересно, как будем рассуждать.
2. То же самое, что п. 1, только абсолютное большинство наборов записываемых данных могут пересекаться по отдельным измерениям. Как рассуждаем в этой ситуации?
3. То же самое, что в п. 1, только теперь чтение приоритетнее записи, запись к примеру делается фоновым режимом, в ночное время. Чтение же должно выполняться быстро. Часто читается физическая таблица регистра.
4. Регистр сведений, непериодический. Несколько измерений (2-3), один ресурс. Частая запись и частое чтение. Объем новых данных ежедневно — 100-200 строк. Чтение приоритетнее записи.
На период чтения пересекающихся наборов данных из одного потока, все остальные потоки должны курить в сторонке. На запись тоже самое.
5. То же самое, что п. 4, только никто курить не должен, все читают и не мешают друг другу. На запись также.
Может несколько сумбурно, но просьба прокомментировать ход мыслей
(71) Dach, да, все любят рассуждать про индексы, кто-то даже любит рассуждать про оптимизацию. Но никто особо не касается проблемы проектирования на примерах из математики вычислений, которые делает программа СУБД, чтобы возвратить результат. А это и есть самый важный момент.
Собственно, программа СУБД пытается оптимизировать запрос с целью совершить минимальное количество чтений из файла данных. ОТ этого и надо отталкиваться. Если у поля есть индекс, то поиск первой записи, удовлетворяющей условиям отбора по данной колонке, происходит в среднем за log2(N)/2 чтений индекса, если индекс представляет из B-TREE (двоичное дерево) и его подвиды (+/*). Это как найти нужную страницу в книге, перелистывая ее вперед/назад, или как угадывание возраста по больше/меньше. Также существуют индексы на основе хеш-функций, но с ними отдельный момент:
[quote]Важное свойство хеш-таблиц состоит в том, что, при некоторых разумных допущениях, все три операции (поиск, вставка, удаление элементов) в среднем выполняются за время O(1). Но при этом не гарантируется, что время выполнения отдельной операции мало́. Это связано с тем, что при достижении некоторого значения коэффициента заполнения необходимо осуществлять перестройку индекса хеш-таблицы: увеличить значение размера массива H и заново добавить в пустую хеш-таблицу все пары.[/quote] — wiki.
Помимо этого, также нужно понимать, что индексы помогают очень быстро найти нужный элемент, но при этом влияют на время вставки (если это не достигший «вырождения» хеш-индекс). Всех больше влияет на это кластерный индекс, ибо по нему сортируются элементы в файле базы данных (разумеется там закладывается резерв и элементы часто вставляются с пропусками для будущих инсёртов). Отсюда простая мораль: если у вас есть регистр с контрагентом, соглашением и суммой, то при в среднем одном договоре у одного контрагента особого смысла в индексе по договору нет, если Вы в запросах не будете присоединять эту таблицу именно по договору без контрагента. Но т.к. 1С все-равно построит индекс по всем измерениям, то повлиять на это без удаления индекса средствами не 1С Вы особо не сможете.
Таким образом могу сказать, что все должно идти из архитектуры решения целиком. Грохаете индекс по договору — соединяйтесь по контрагенту и договору всегда вместе. Нужны данные только по договору — делайте индекс на договоры. Отбираете по четырем полям — проиндексируйте одно основное, остальные найдутся рядом.
Если скорость отбора приоритетна перед записью и уникальность данных всех полей достаточно высокая — проиндексируйте все. Но если для двух первых полей третье и четвертое — это два-три варианта, то смысла добавлять их в индекс особого нет.
Источник: infostart.ru
SQL
Индексы
Индексы представляют собой структуру данных, содержащую указатели на содержимое таблицы, упорядоченной в определенном порядке, чтобы помочь оптимизировать запросы базы данных. Они похожи на индекс книги, где страницы (строки таблицы) индексируются по их номеру страницы.
Существует несколько типов индексов и могут быть созданы на столе. Когда индекс существует в столбцах, используемых в предложении WHERE запроса, в предложении JOIN или в предложении ORDER BY, он может существенно повысить производительность запросов.
замечания
Индексы являются способом ускорения запросов на чтение путем сортировки строк таблицы в соответствии с столбцом.
Эффект индекса не заметен для небольших баз данных, таких как пример, но если имеется большое количество строк, это может значительно повысить производительность. Вместо проверки каждой строки таблицы сервер может выполнять двоичный поиск по индексу.
Компромисс для создания индекса — скорость записи и размер базы данных. Хранение индекса занимает пробел. Кроме того, каждый раз, когда выполняется INSERT или обновляется столбец, индекс должен обновляться. Это не такая дорогостоящая операция, как сканирование всей таблицы в запросе SELECT, но это все еще нужно иметь в виду.
Создание индекса
Это создаст индекс для столбца EmployeeId в таблице Cars . Этот индекс улучшит скорость запросов, запрашивающих сервер для сортировки или выбора значений в EmployeeId , например:
Индекс может содержать более 1 столбца, как в следующем;
В этом случае индекс был бы полезен для запросов, запрашивающих сортировку или выбор всех включенных столбцов, если набор условий упорядочен таким же образом. Это означает, что при извлечении данных он может найти строки, которые будут извлекаться с использованием индекса, а не просматривать всю таблицу.
Например, в следующем случае будет использоваться второй индекс;
Однако, если порядок отличается, индекс не имеет таких же преимуществ, как в следующем;
Индекс не так полезен, потому что база данных должна извлекать весь индекс по всем значениям EmployeeId и CarID, чтобы определить, какие элементы имеют OwnerId = 17 .
(Индекс все еще может быть использован, возможно, оптимизатор запросов обнаруживает, что извлечение индекса и фильтрация на OwnerId , а затем получение только необходимых строк выполняется быстрее, чем извлечение полной таблицы, особенно если таблица большая.)
Кластерные, уникальные и отсортированные индексы
Индексы могут иметь несколько характеристик, которые могут быть установлены либо при создании, либо путем изменения существующих индексов.
Вышеупомянутый оператор SQL создает новый кластерный индекс для Employees. Кластеризованные индексы — это индексы, которые определяют фактическую структуру таблицы; сама таблица сортируется в соответствии со структурой индекса. Это означает, что на таблице может быть не более одного кластеризованного индекса. Если кластерный индекс уже существует в таблице, вышеуказанный оператор не будет выполнен. (Таблицы без кластеризованных индексов также называются кучами.)
Это создаст уникальный индекс для столбца Email в таблице Customers . Этот индекс, наряду с ускорением запросов, таких как нормальный индекс, также заставит каждый адрес электронной почты в этом столбце быть уникальным. Если строка вставлена или обновлена с нестандартным значением электронной почты , вставка или обновление по умолчанию будут неудачными.
Это создает индекс для клиентов, который также создает ограничение таблицы, в котором EmployeeID должен быть уникальным. (Это не удастся, если столбец в настоящее время не уникален — в этом случае, если есть сотрудники, которые имеют идентификатор).
Это создает индекс, который сортируется в порядке убывания. По умолчанию индексы (по крайней мере, на сервере MSSQL) возрастают, но их можно изменить.
Вставка с уникальным индексом
Это приведет к сбою, если в столбце Электронная почта Клиентов установлен уникальный индекс. Однако для этого случая можно определить альтернативное поведение:
SAP ASE: индекс падения
Эта команда уменьшит индекс в таблице. Он работает на сервере SAP ASE .
Синтаксис:
Пример:
Сортированный указатель
Если вы используете индекс, который сортируется так, как вы его извлекли, SELECT не будет выполнять дополнительную сортировку при поиске.
Когда вы выполняете запрос
Система базы данных не будет выполнять дополнительную сортировку, поскольку она может выполнять поиск по индексу в этом порядке.
Удаление индекса, или отключение и восстановление его
Мы можем использовать команду DROP для удаления нашего индекса. В этом примере мы будем DROP индексом ix_cars_employee_id на столе Cars .
Это полностью исключает индекс, и если индекс кластеризуется, удаляется любая кластеризация. Он не может быть перестроен без воссоздания индекса, который может быть медленным и дорогостоящим. В качестве альтернативы индекс можно отключить:
Это позволяет таблице сохранить структуру вместе с метаданными об индексе.
Критически это сохраняет статистику индекса, так что можно легко оценить изменение. Если это оправдано, индекс затем может быть перестроен, а не полностью восстановлен;
Уникальный индекс, который позволяет NULLS
Эта схема допускает отношения 0..1 — люди могут иметь ноль или одну водительскую лицензию, и каждая лицензия может принадлежать только одному человеку
Перестроить индекс
С течением времени индексы B-Tree могут стать фрагментированными из-за обновления / удаления / вставки данных. В терминологии SQLServer у нас может быть внутренняя (индексная страница, наполовину пустая) и внешняя (логический порядок страниц не соответствует физическому порядку). Индекс перестройки очень похож на падение и воссоздание.
Мы можем перестроить индекс с помощью
По умолчанию индекс перестройки — это автономная операция, которая блокирует таблицу и предотвращает DML, но многие RDBMS позволяют осуществлять онлайн-перестройку. Кроме того, некоторые поставщики БД предлагают альтернативы перестройке индекса, такие как REORGANIZE (SQLServer) или COALESCE / SHRINK SPACE (Oracle).
Кластерный индекс
При использовании кластерного индекса строки таблицы сортируются по столбцу, к которому применяется кластерный индекс. Поэтому в таблице может быть только один кластерный индекс, потому что вы не можете упорядочить таблицу двумя разными столбцами.
Как правило, лучше использовать кластерный индекс при выполнении чтения в больших таблицах данных. Домен кластеризованного индекса заключается в том, чтобы писать в таблицу, и данные необходимо реорганизовать (прибегать).
Пример создания кластерного индекса в таблице Сотрудники в столбце Employee_Surname:
Некомпилированный индекс
Некластеризованные индексы хранятся отдельно от таблицы. Каждый индекс в этой структуре содержит указатель на строку в таблице, которую он представляет.
Эти указатели называются локаторами строк. Структура локатора строк зависит от того, хранятся ли страницы данных в куче или кластеризованной таблице. Для кучи указатель строки является указателем на строку. Для кластерной таблицы локатор строк представляет собой кластерный индексный ключ.
Пример создания некластеризованного индекса в таблице Сотрудники и столбец Employee_Surname:
В таблице может быть несколько некластеризованных индексов. Операции чтения, как правило, медленнее с некластеризованными индексами, чем с кластеризованными индексами, так как вам нужно сначала индексировать, а не таблицу. Однако никаких ограничений в операциях записи нет.
Частичный или отфильтрованный указатель
SQL Server и SQLite позволяют создавать индексы, которые содержат не только подмножество столбцов, но и подмножество строк.
Рассмотрим постоянное возрастающее количество заказов с order_state_id равным завершенному (2), и стабильное количество заказов с order_state_id equal (1).
Если ваш бизнес использует такие запросы:
Частичная индексация позволяет вам ограничить индекс, включая только незавершенные заказы:
Этот индекс будет меньше, чем нефильтрованный индекс, что экономит место и снижает стоимость обновления индекса.
Источник: learntutorials.net