Индексы широко используются во многих хранилищах данных. Хотя их реализации в хранилище данных может различаться, они используются для более эффективного поиска по столбцу (или набору столбцов). Дополнительные сведения о правильном использовании индексов см. в разделе об индексах в документации по производительности.
Индекс для столбца можно указать следующим образом:
- Заметки к данным
- Текучий API
Настройка индексов с помощью заметок к данным появилась в EF Core 5.0.
По соглашению индекс создается в каждом свойстве (или наборе свойств), используемом в качестве внешнего ключа.
EF Core поддерживает только один индекс для каждого отдельного набора свойств. Если настроить индекс для набора свойств, для которого уже определен индекс, в соответствии с соглашением или предыдущей конфигурацией, то будет изменено определение этого индекса. Это полезно, если необходимо дополнительно настроить индекс, созданный по соглашению.
Составной индекс
Индекс может также охватывать более одного столбца:
Индексы SQL | Что такое индексы, разновидности, как работают?
- Заметки к данным
- Текучий API
Индексы по нескольким столбцам, также известные как составные индексы, ускоряют запросы, которые фильтруются по столбцам индекса, а также запросы, которые фильтруются только по первым столбцам, охватываемым индексом. Дополнительные сведения см. в документации по производительности.
Уникальность индекса
По умолчанию индексы не являются уникальными: несколько строк могут содержать одинаковые значения для набора столбцов индекса. Сделать индекс уникальным можно следующим образом:
- Заметки к данным
- Текучий API
При попытке вставить более одной сущности с одинаковыми значениями для набора столбцов индекса возникнет исключение.
Порядок сортировки индексов
Эта возможность появилась в EF Core 7.0.
В большинстве баз данных каждый столбец, охватываемый индексом, можно упорядочить либо по возрастанию, либо по убыванию. Для индексов, охватывающих только один столбец, обычно это не имеет значения. При необходимости база данных может проходить по индексу в обратном порядке. Но при использовании составных индексов порядок может иметь решающее значение для производительности и определять, используется ли индекс запросом. Как правило, порядок сортировки столбцов индекса должен соответствовать указанному в предложении ORDER BY запроса.
По умолчанию используется порядок сортировки индекса по возрастанию. Вы можете упорядочить все столбцы по убыванию следующим образом:
- Заметки к данным
- Текучий API
Кроме того, вы можете указать порядок сортировки по столбцам следующим образом:
- Заметки к данным
- Текучий API
Имя индекса
По соглашению, индексы, созданные в реляционной базе данных, называются IX__ . Для составных индексов преобразуется в список имен свойств с разделителями символом подчеркивания.
Что такое фондовые индексы и зачем они нужны?
Вы можете задать имя индекса, созданного в базе данных:
- Заметки к данным
- Текучий API
Фильтр индекса
Некоторые реляционные базы данных позволяют указать отфильтрованный или частичный индекс. Это позволяет индексировать только часть значений столбца, уменьшая размер индекса, повышая производительность и оптимизируя использование дискового пространства. Дополнительные сведения об отфильтрованных индексах SQL Server см. в документации.
Вы можете использовать Fluent API для указания фильтра по индексу, который предоставляется в виде SQL-выражения:
При использовании поставщика SQL Server EF добавляет фильтр ‘IS NOT NULL’ для всех столбцов, допускающих значение NULL, которые являются частью уникального индекса. Чтобы переопределить это соглашение, можно указать значение null .
Включенные столбцы
Некоторые реляционные базы данных позволяют настроить набор столбцов, которые включены в индекс, но не являются частью ключа. Это может значительно повысить производительность запросов, если все столбцы в запросе включены в индекс как ключевые или неключевые, так как к самой таблице можно будет не получать доступ. Дополнительные сведения о включенных столбцах в SQL Server см. в документации.
Проверочные ограничения
Проверочные ограничения — это стандартная реляционная функция, позволяющая определить условие, которое должно выполняться для всех строк в таблице. Любая попытка вставить или изменить данные, нарушающие ограничение, завершится ошибкой. Проверочные ограничения похожи на ограничения, запрещающие значение NULL в столбце, или на ограничения, которые запрещают дублирование, но они позволяют определять произвольное SQL-выражение.
Вы можете использовать Fluent API, чтобы указать проверочное ограничение для таблицы в виде SQL-выражения:
В одной таблице можно определить несколько проверочных ограничений, каждое с отдельным именем.
Примечание. Некоторые распространенные проверочные ограничения можно настроить с помощью пакета от сообщества EFCore.CheckConstraints.
Источник: learn.microsoft.com
Токарчук Андрей
Типы индексов, виды индексов, или какие вообще бывают индексы?
После прочтения многочисленной литературы по СУБД, некоторого опыта работы с MongoDB и листанию статей по базам данных у меня созрело желание сделать cheatsheet по индексам применительно к БД. А индексирование — достаточно интересный раздел теории баз данных, а главное — нужный в практике. Вообще-то говоря, золотое правило индексирования — иметь индекс под каждый запрос.
По порядку сортировки
- Упорядоченные — индексы, в которых элементы поля(столбца) упорядочены.
- Возрастающие
- Убывающие
По источнику данных
- Индексы по представлению (view).
- Индексы по выражениям — например в PostgreSQL.
По воздействию на источник данных
- Некластерный индекс — наиболее типичные представители семейства индексов. В отличие от кластерных, они не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки. Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя: информацию об идентификационном номере файла, в котором хранится строка; идентификационный номер страницы соответствующих данных; номер искомой строки на соответствующей странице; содержимое столбца.
- Кластерный индекс — Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту. Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными.
По структуре

По количественному составу
- Простой индекс (индекс с одним ключом) — строится по одному полю.
Составной (многоключевой, композитный) индекс — строится по нескольким полям. Важен порядок следования полей (например в MongoDB).
Индекс с включенными столбцами — Некластеризованный индекс, дополнительно содержащий кроме ключевых столбцов еще и неключевые. - Главный индекс (индекс по первичному ключу) — это тот индексный ключ, под управлением которого в данный момент находится таблица. Таблица не может быть отсортирована по нескольким индексным ключам одновременно. Хотя, если одна и та же таблица открыта одновременно в нескольких рабочих областях, то у каждой копии таблицы может быть назначен свой главный индекс.
По характеристике содержимого
- Уникальный индекс — состоит из множества уникальных значений поля.
Плотный индекс (NoSQL) — индекс, при котором, каждом документе в индексируемой коллекции соответствует запись в индексе, даже если в документе нет индексируемого поля. - Разреженный индекс (NoSQL) — тот, в котором представлены только те документы, для которых индексируемый ключ имеет какое-то определённое значение (существует).
- Пространственный индекс — оптимизирован для описания географического местоположения. Представляет из себя многоключевой индекс состоящий из широты и долготы.
- Составной пространственный индекс — индекс, включающий в себя кроме широты и долготы ещё какие-либо мета-данные (например теги). Но географические координаты должны стоять на первом месте.
- Полнотекстовый (инвертированный) индекс — словарь, в котором перечислены все слова и указано, в каких местах они встречаются. При наличии такого индекса достаточно осуществить поиск нужных слов в нём и тогда сразу же будет получен список документов, в которых они встречаются.
- Хэш-индексы — предполагают хранение не самих значений, а их хэшей, благодаря чему уменьшается размер(а, соответственно, и увеличивается скорость их обработки) индексов из больших полей. Таким образом, при запросах с использованием HASH-индексов, сравниваться будут не искомое со значения поля, а хэш от искомого значения с хэшами полей.
Из-за нелинейнойсти хэш-функций данный индекс нельзя сортировать по значению, что приводит к невозможности использования в сравнениях больше/меньше и «is null». Кроме того, так как хэши не уникальны, то для совпадающих хэшей применяются методы разрешения коллизий. - Битовый индекс (bitmap index) — метод битовых индексов заключается в создании отдельных битовых карт (последовательность 0 и 1) для каждого возможного значения столбца, где каждому биту соответствует строка с индексируемым значением, а его значение равное 1 означает, что запись, соответствующая позиции бита содержит индексируемое значение для данного столбца или свойства.
- Обратный индекс (reverse index) — это тоже B-tree индекс но с реверсированным ключом, используемый в основном для монотонно возрастающих значений(например, автоинкрементный идентификатор) в OLTP системах с целью снятия конкуренции за последний листовой блок индекса, т.к. благодаря переворачиванию значения две соседние записи индекса попадают в разные блоки индекса. Он не может использоваться для диапазонного поиска.
- Функциональный (function-based) индекс (индекс по вычисляемому полю) — индекс, ключи которого хранят результат пользовательских функций. Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Создание функционального индекса с функцией UPPER улучшает эффективность таких сравнений. Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД(кроме, пожалуй, битового индекса, например, Hash для Oracle)
- Первичный индекс — уникальный индекс по полю первичного ключа.
- Вторичный индекс — индекс по другим полям (кроме поля первичного ключа).
- XML-индекс — вырезанное материализованное представление больших двоичных XML-объектов (BLOB) в столбце с типом данных xml.
По механизму обновления
- Полностью перестраиваемый — при добавлении элемента заново перестраивается весь индекс.
- Пополняемый (балансируемый) — при добавлении элементов индекс перестраивается частично (например одна из ветви) и периодически балансируется.
По покрытию индексируемого содержимого
- Полностью покрывающий (полный) индекс — покрывает всё содержимое индексируемого объекта.
- Частичный (partial) индекс — это индекс, построенный на части таблицы, удовлетворяющей определенному условию самого индекса. Данный индекс создан для уменьшения размера индекса.
- Инкрементный (Delta) индекс — индексируется малая часть данных(дельта), как правило, по истечении определённого времени. Используется при интенсивной записи. Например, полный индекс перестраивается раз в сутки, а дельта-индекс строится каждый час. По сути это частичный индекс по временной метке.
- Real-time индекс — особый вид delta индекса в Sphinx, характеризующийся высокой скоростью построения. Предназначен для часто-меняющихся данных.
Индексы в кластерных системах
- Глобальный индекс — индекс по всему содержимому всех shard’ов (секций).
- Сегментный индекс — глобальный индекс по полю-сегментируемому ключу (shard key). Используется для быстрого определения сегмента(shard’а), на котором хранятся данные в процессе маршрутизации запроса в кластере БД.
- Локальный индекс — индекс по содержимому только одного shard’а.
Если есть неточности, коррективы — пишите в комменты. Надеюсь кому-то будет полезным эта «шпаргалка».
Ссылки
Спасибо!
Если вам помогла статья, или вы хотите поддержать мои исследования и блог — вот лучший способ сделать это:
6 комментариев to “Типы индексов, виды индексов, или какие вообще бывают индексы?”
Душевно изложили. Шпаргалка и впрямь интересна, а вот если снабдить каждую характеристику use case’ом, вообще цены бы не было

Андрей Токарчук :
Спасибо, Алекс. Чего-то вот ночью гуглил-гуглил, и решил разрозненные сведения в одно место собрать. А насчёт use-case так это к каждому отдельно не сделаешь, надо по ситуации смотреть
А в чем разница между индексом по вычисляему полю и функциональным?
Андрей Токарчук :
Это одно и тоже. Подкорректировал пост.
Вот интересный электронная книга по теме. Думаю начать её переводить.
Андрей Токарчук :
Источник: tokarchuk.ru
Индексируем подразделения организации: как?
Индексы подразделений нужны в разных рабочих ситуациях. Например, при составлении номенклатуры дел в строке «Раздел» указывается код структурного подразделения, который также станет первой частью индексов всех его дел. При внедрении СЭД, когда для каждого отдела заводится специальная папка в системе, также используют его индекс. Наконец, отдел кадров и бухгалтерия в некоторых документах заполняют поле «Код структурного подразделения». В статье мы расскажем, как правильно присваивать индексы структурным подразделениям и филиалам организации.
ГЛАВНОЕ – СОГЛАСОВАННОСТЬ
Казалось бы, придумать коды для подразделений несложно. Но именно в этой простоте и заключается главная проблема индексации. Случается, что одно подразделение, например отдел кадров, индексирует все отделы организации, но не считает нужным информировать об этом коллег из других отделов и руководство.
Через некоторое время делопроизводители берутся за составление номенклатуры дел, в результате чего у подразделений оказывается уже по два разных индекса.
А затем ИТ-специалисты составляют большой телефонный справочник внутренних номеров и присваивают всем отделам индексы уже по собственному усмотрению…
Так может продолжаться сколько угодно долго, пока не настанет день, когда окажется, что номеров существует множество, но официального индекса нет ни у одного из подразделений, при этом никто не хочет отказываться от своих разработок.

Таким образом, чтобы не повторять сюжет классической басни про лебедя, щуку и рака, нужно сделать простую вещь: утвердить коды структурных подразделений на уровне решения первого лица, то есть издать соответствующий приказ. А предварительно выяснить, не проводилась ли индексация подразделений ранее.
Как показала описанная ситуация, для этого нужно не только проанализировать изданные распорядительные документы, но и опросить руководителей структурных подразделений.
ЧТО ТАКОЕ ИНДЕКС ПОДРАЗДЕЛЕНИЯ?
Индекс подразделения организации – как структурного, так и обособленного – это уникальный код, в котором зашифрована информация об этом подразделении.
Состав зашифрованной в коде информации может быть каким угодно. Например:
• порядковый номер подразделения в соответствии с организационной структурой;
• функционал подразделения и др.

Части индексов могут отделяться друг от друга любыми знаками, но наиболее распространены косая черта, дефис и точка. Например:
12 – простой порядковый номер подразделения в соответствии с организационной структурой;
ТД/2 – второе подразделение в технической дирекции;
УП/ОТиЗ – отдел труда и заработной платы в управлении по персоналу;
ДП.V-Сиб – дирекция по продажам в пятом филиале организации по Сибирскому федеральному округу.

ИНДЕКСАЦИЯ ПОДРАЗДЕЛЕНИЙ В ОРГАНИЗАЦИЯХ С ПРОСТОЙ СТРУКТУРОЙ
Первый уровень индексов. Самый простой способ проиндексировать подразделения – присвоить им порядковые номера (01, 02, 03 и т.д.). Таких индексов будет более чем достаточно для номенклатуры дел и заполнения форм документов в кадровом делопроизводстве, а также для сокращенного наименования подразделений во внутренних документах.
Без особой необходимости усложнять их нет смысла.
Этот способ подходит для индексации подразделений организации, имеющей простую структуру, – довольно крупной, но без филиалов (Схема 1).
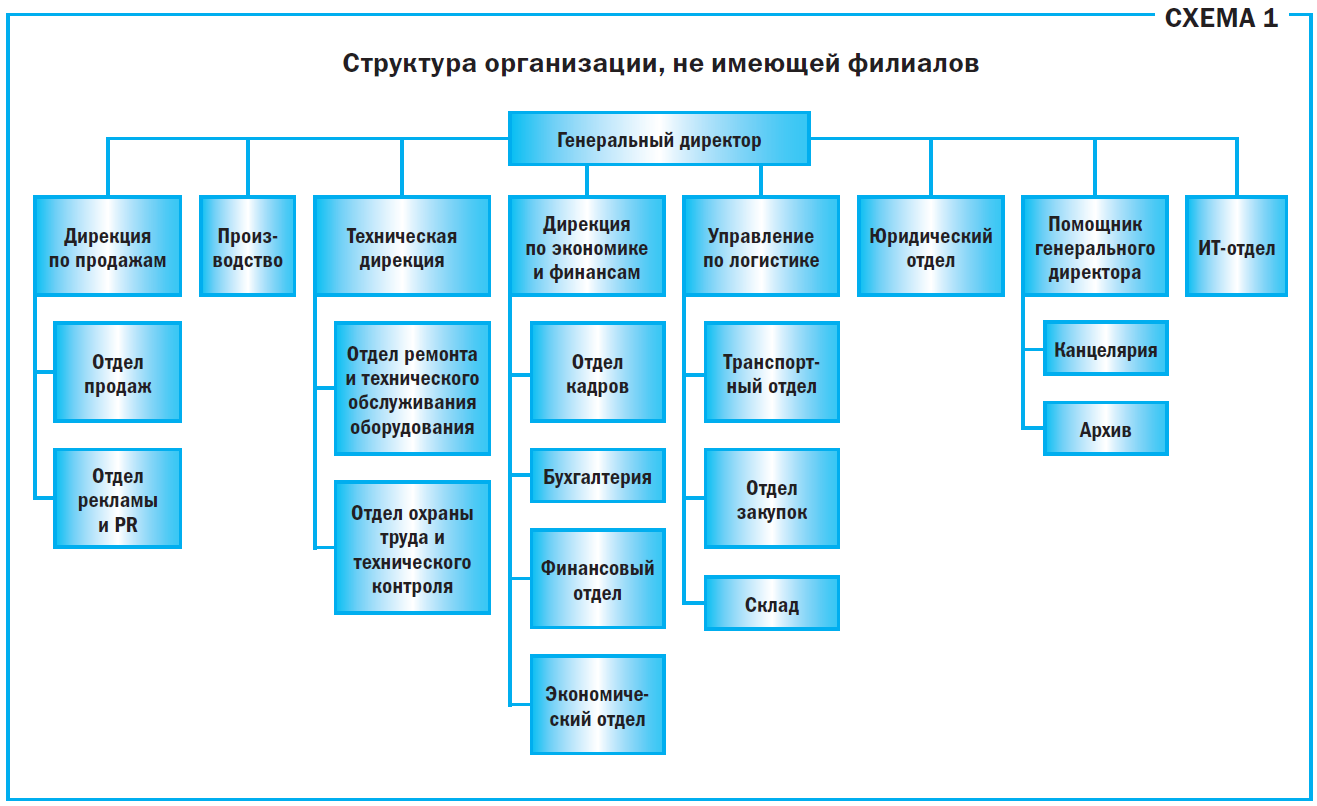
Из Схемы 1 видно, что генеральному директору напрямую подчинены помощник генерального директора, а также руководители следующих подразделений:
• дирекция по продажам;
• дирекция по экономике и финансам;
• управление по логистике;
Помощник генерального директора руководит канцелярией и архивом – он отвечает за все делопроизводство организации и аккумулирует у себя все организационно-правовые и распорядительные документы, а также часть информационно-справочных документов топ-менеджеров. Поэтому условное подразделение, за которое он отвечает, принято обозначать как «Руководство».
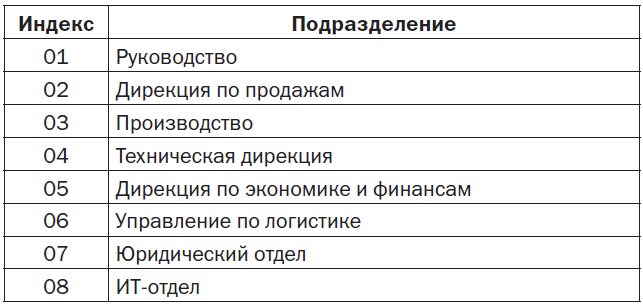
Таким образом, индексы первого уровня будут выглядеть так:
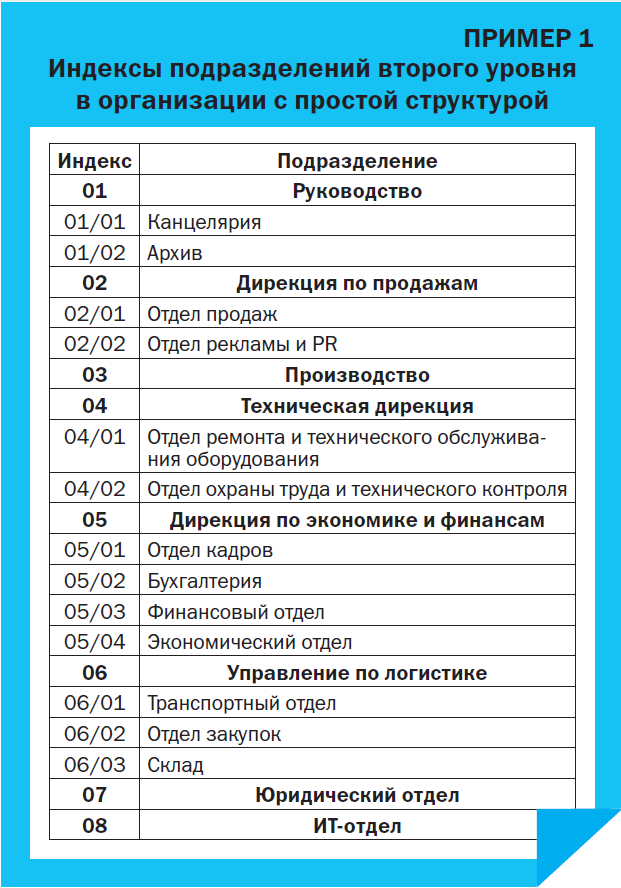
Второй уровень индексов. В ряде случаев на этом индексацию можно завершить. Но если дирекция и управления делятся на отделы (см. Схему 1), индексацию продолжают – вводят индексы второго уровня (Пример 1).
Между частями индекса мы ставим косую черту. Все дополнения к этим обозначениям, например порядковые номера дел по номенклатуре, будут указываться через дефис: 06/02-01.
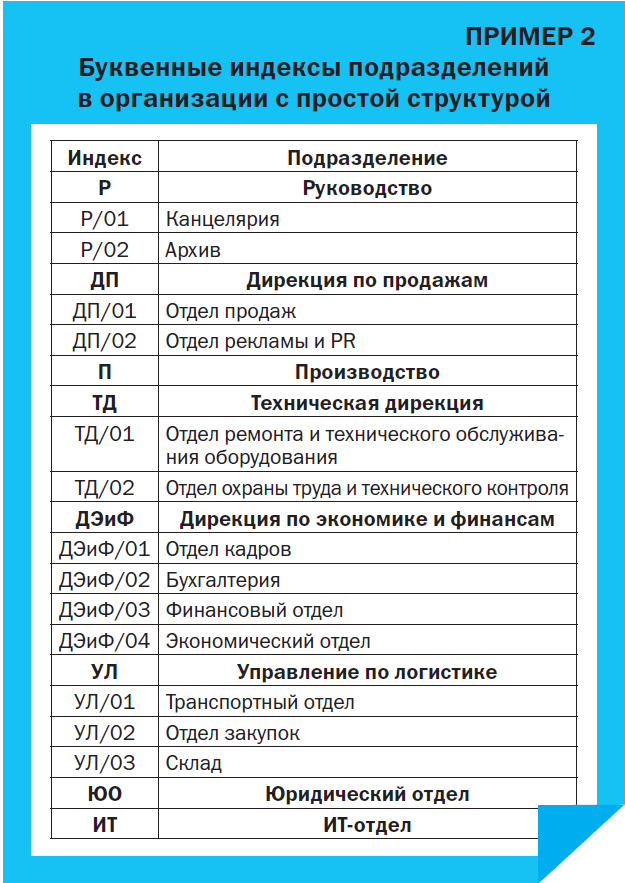
Буквенный индекс. На наш взгляд, более информативным является другой способ индексации: подразделения первого уровня обозначаются буквами, благодаря чему идентифицируются легче, а отделы второго уровня получают дополнительные числовые обозначения (Пример 2).
ИНДЕКСАЦИЯ ПОДРАЗДЕЛЕНИЙ В ОРГАНИЗАЦИЯХ СО СЛОЖНОЙ СТРУКТУРОЙ
Необходимость составлять сложные индексы для подразделений возникает в случае, если организация имеет сложную структуру, например у нее есть сеть филиалов, или вовсе является холдингом (группой компаний).
«Простыми» индексами здесь не обойтись. Индекс будет состоять как минимум из двух, а скорее всего, трех или четырех частей.
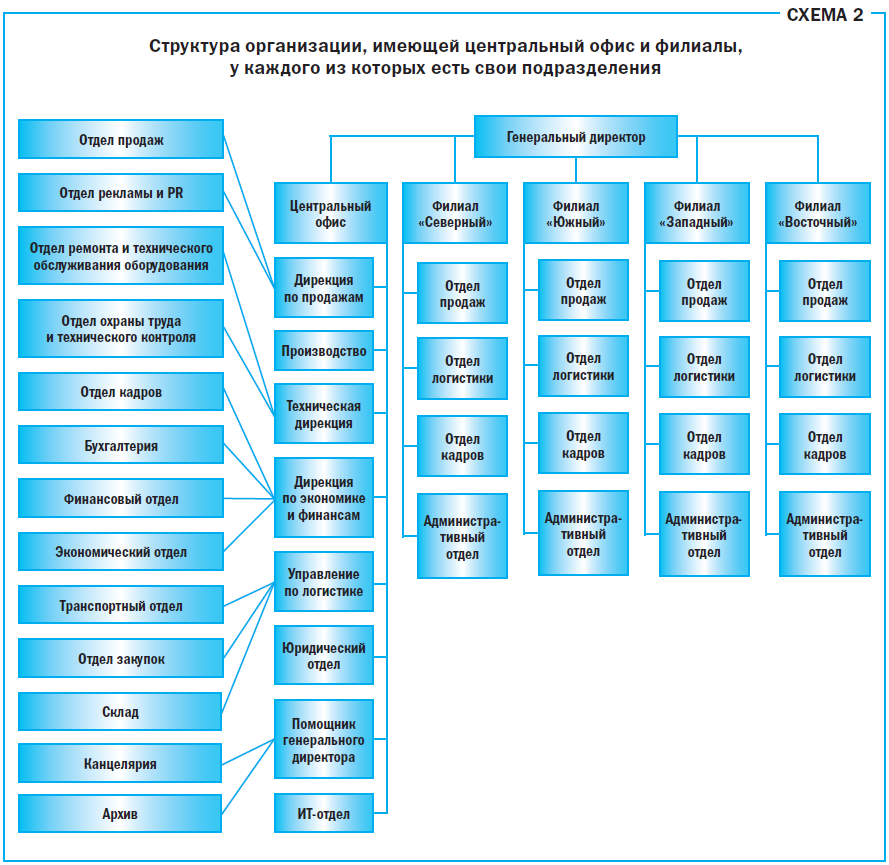
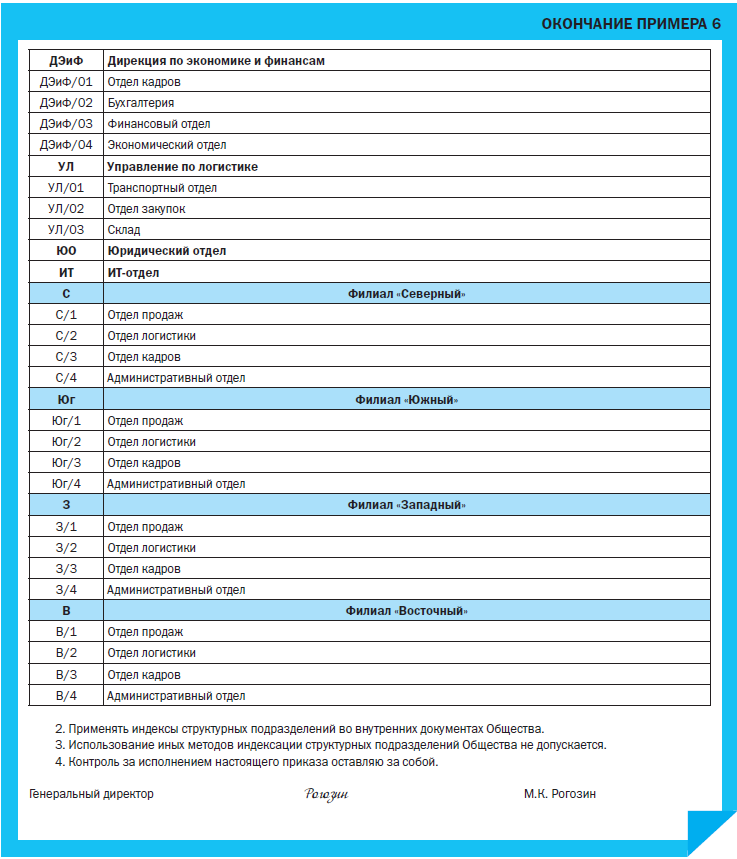
На Схеме 2 показана структура организации с центральным офисом и четырьмя филиалами, каждый из которых имеет по четыре подразделения.
И в этом случае общий принцип индексации остается неизменным: подразделения получают уникальные числовые или буквенные коды.
Если ваша организация имеет разветвленную структуру, используйте буквенные индексы уже на первом уровне индексации – буквы воспринимаются легче, чем числа.
Индексы первого уровня в организации из нашего примера могут выглядеть так:

Разные буквы для подразделений первого уровня исключают повторение индексов. В нашем упрощенном примере не составило труда обозначить четыре филиала разными буквами. Но на практике филиалов может быть и несколько десятков. Однако в любом случае трудности здесь вполне преодолимы.

Индексы второго уровня. Вернемся к нашему примеру и проставим индексы второго уровня, причем начнем с филиалов.
В каждом из них по 4 отдела: отделы продаж, логистики, кадров и административный отдел. Выберем для них числовые обозначения (Пример 3).

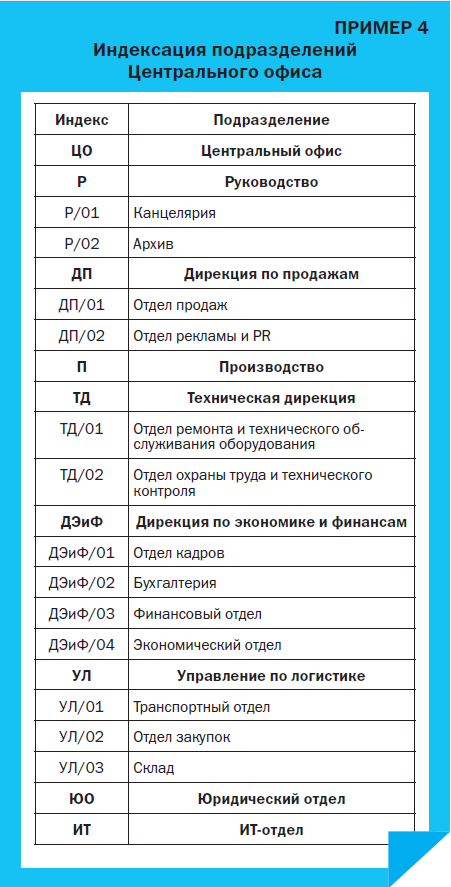
Индексация подразделений Центрального офиса.
Что касается индексов для центрального офиса и его подразделений, то кажется логичным пойти по тому же принципу и связать индекс первого уровня ЦО с буквенными индексами второго уровня Р, ДП и др. и получить ЦО-Р и ЦО-ДП. Но здесь нужно остановиться и вспомнить о правилах индексации: соблюдать уникальность и не помещать в индекс ненужной информации.
Обозначение ЦО, равно как и буквенные обозначения подразделений центрального офиса первого уровня в нашей организации, больше не встречается ни в одном из филиалов или подразделений. Поэтому мы оставим ЦО для обозначения центрального офиса, а его подразделения обозначим индексами, состоящими из двух частей.
Мы делаем это, чтобы не помещать в индексы лишней информации: и так понятно, что, например, ДЭиФ существует только в главном офисе организации, не нужно сообщать об этом лишний раз (Пример 4).
ИНДЕКСЫ НА ПРАКТИКЕ
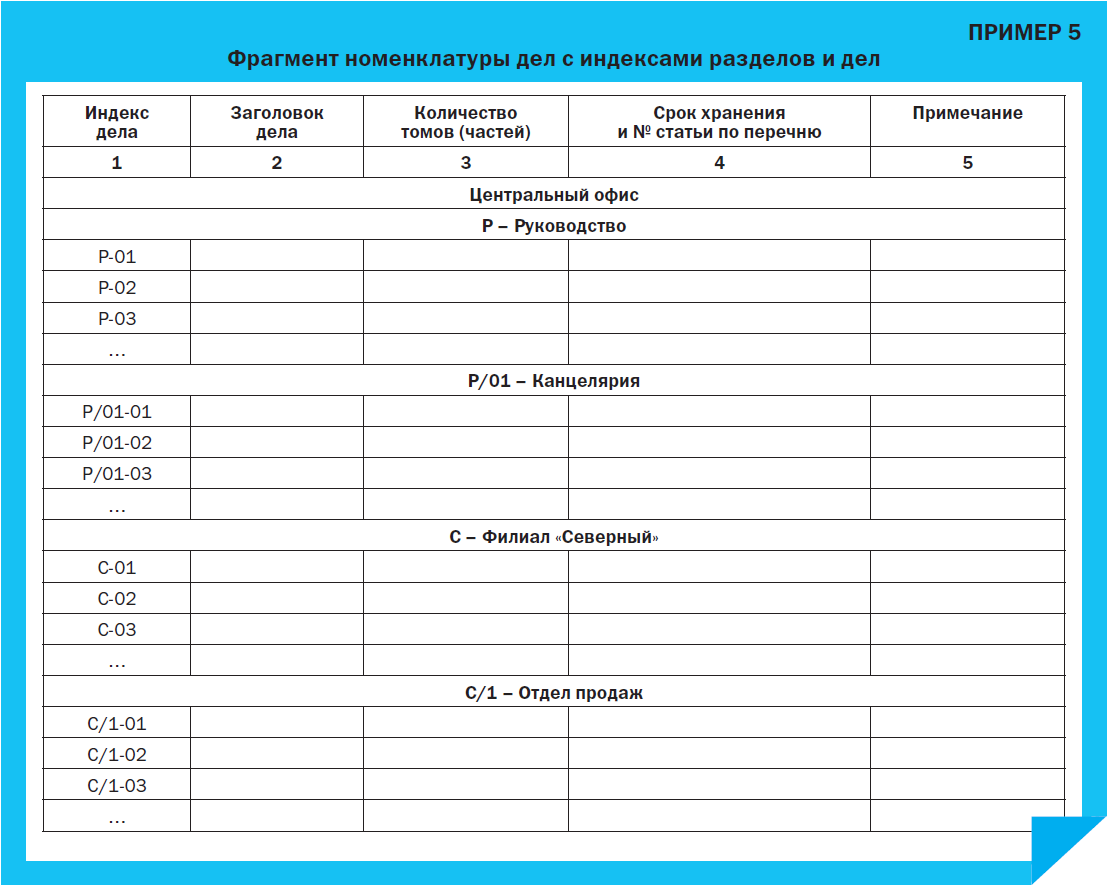
■ Индексы в номенклатуре дел. Приведем пример обозначения разделов и индексов дел по номенклатуре: очевидно, что индексы дел будут отличаться от стандартных 01/02 и других (Пример 5).
Однако это вполне допустимо, ведь наша цель – создать читаемые, а не формальные индексы, и к документам это относится тоже.
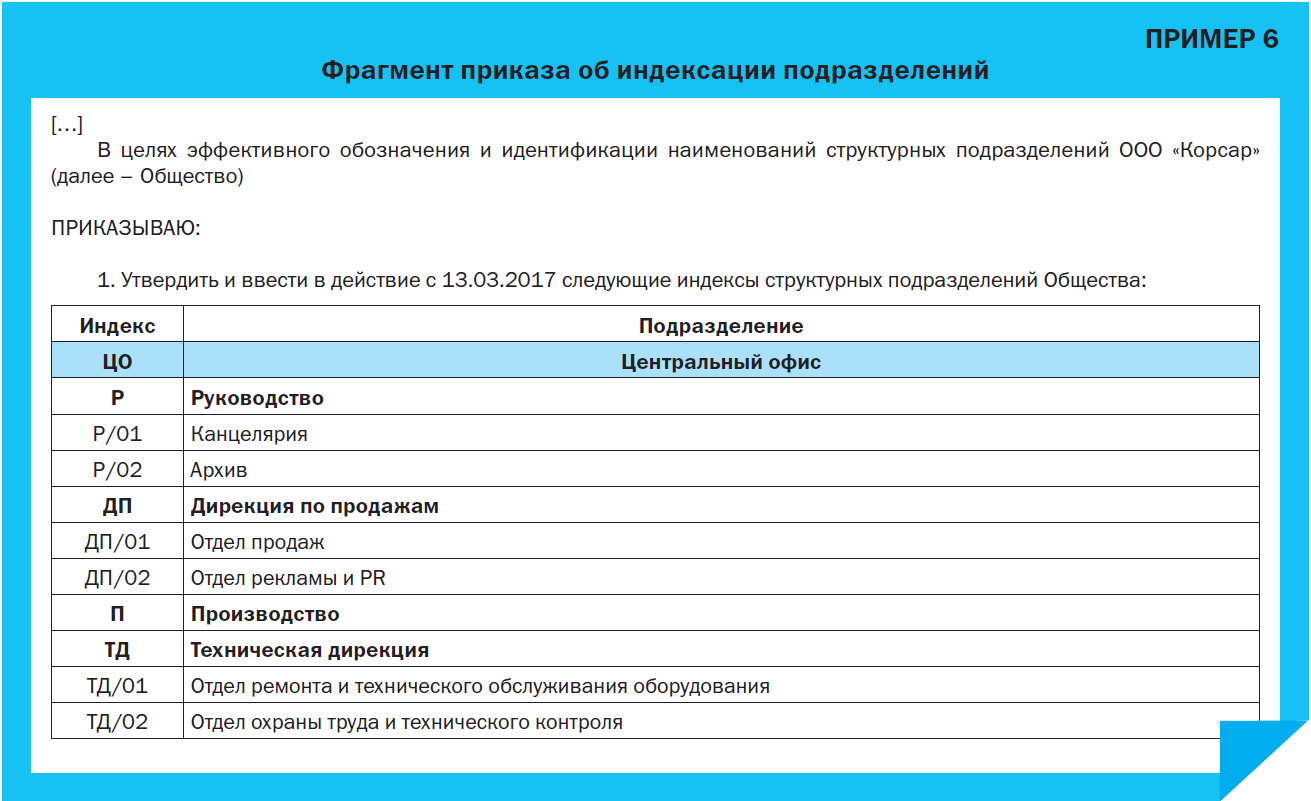
■ Приказ об индексации подразделений организации. Какой бы способ индексации ни был избран, его нужно закрепить на самом высоком уровне – издать приказ по основной деятельности.
В констатирующую часть приказа принято выносить основание для его издания.
Поскольку индексация подразделений используется во многих процессах, нет необходимости перечислять их все. Лучше обойтись общей формулировкой (Пример 6).
РЕЗЮМЕ
1. Прежде чем индексировать подразделения организации по собственной инициативе, нужно выяснить, не проводилась ли индексация ранее.
2. Индексы должны быть уникальными и не перегруженными лишней информацией.
3. Простейший индекс – числовой (01, 02, 03 и т.д.). Кроме того, индексы могут быть буквенными, а также комбинированными. Буквы в индексах воспринимаются легче, чем числа, и являются более информативными.
4. Любое усложнение индекса должно быть оправдано. Если можно остановиться на простых числовых обозначениях, то лучше так и сделать.
Источник: www.profiz.ru